SciPy K-Means
SciPy K-Means : Package scipy.cluster.vp provides kmeans() function to perform k-means on a set of observation vectors forming k clusters. In this tutorial, we shall learn the syntax and the usage of kmeans() function with SciPy K-Means Examples.
Syntax
centroids,distortion = scipy.cluster.vq.kmeans(obs, k_or_guess, iter=20, thresh=1e-05, check_finite=True)Try Online
| Parameter | Optional/ Required | [datatype] Description |
| obs | Required | [ndarray] Each row of the M by N array is an observation vector. The columns are the features seen during each observation. The features must be whitened first with the whiten function. |
| k_or_guess | Required | [int or ndarray] The number of centroids to generate. A code is assigned to each centroid, which is also the row index of the centroid in the code_book matrix generated. |
| iter | Optional | [int] The number of times to run k-means, returning the codebook with the lowest distortion. This argument is ignored if initial centroids are specified with an array for the k_or_guess parameter. This parameter does not represent the number of iterations of the k-means algorithm. |
| thresh | Optional | [float] Terminates the k-means algorithm if the change in distortion since the last k-means iteration is less than or equal to thresh. |
| check_finite | Optional | [boolean] Whether to check that the input matrices contain only finite numbers. Disabling may give a performance gain, but may result in problems (crashes, non-termination) if the inputs do contain infinities or NaNs. Default: True |
| centroids | [Returned value] | [ndarray] A k by N array of k centroids. |
| distortion | [Returned Value] | [float] The distortion between the observations passed and the centroids generated. |
Values provided for the optional arguments are default values.
ADVERTISEMENT
SciPy K-Means Example
In this example, we shall generate a set of random 2-D points, centered around 3 centroids.
# import numpy from numpy import vstack,array from numpy.random import rand # matplotlib import matplotlib.pyplot as plt # scipy from scipy.cluster.vq import kmeans,vq,whiten data = vstack(((rand(20,2)+1),(rand(20,2)+3),(rand(20,2)+4.5))) plt.plot(data[:,0],data[:,1],'go') plt.show()Try Online
# whiten the features
data = whiten(data)
# find 3 clusters in the data
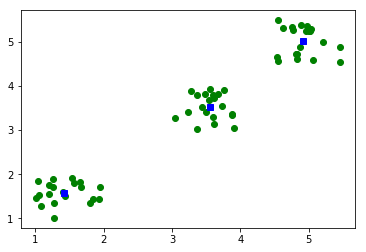
centroids,distortion = kmeans(data,3)
print('centroids : ',centroids)
print('distortion :',distortion)
plt.plot(data[:,0],data[:,1],'go',centroids[:,0],centroids[:,1],'bs')
plt.show() Try Online centroids : [[ 1.42125469 1.58213817] [ 3.55399219 3.53655637] [ 4.91171555 5.02202473]] distortion : 0.35623898893