Get Started
Learn about Minishift in this guest post by Tomasz Adamski, the author of Hands-On Cloud Development with WildFly.
Minishift is a tool that starts a virtual machine on your local computer and creates an OpenShift cluster inside it. As a result, it enables you to try and test a fully featured OpenShift cluster on your local machine. The following sections will explain how to work with Minishift.
Installation
You can download the latest version of Minishift from the GitHub page. You also have to install the virtual machine that you’ll use and configure your environment variables accordingly. The process is very simple and takes a few minutes to complete. The details of the particular installation steps differ a bit between operating systems. They are described thoroughly in the attached installation guide.
Starting the cluster
After you have installed the cluster, you can start it using the minishift start command. It is a good practice to boost the default parameters to provide enough memory and disk space for the services that you will develop and use:
minishift start --memory=4096 --disk-size=30gbAfter you run the preceding command, you have to wait a few minutes for the cluster to start:
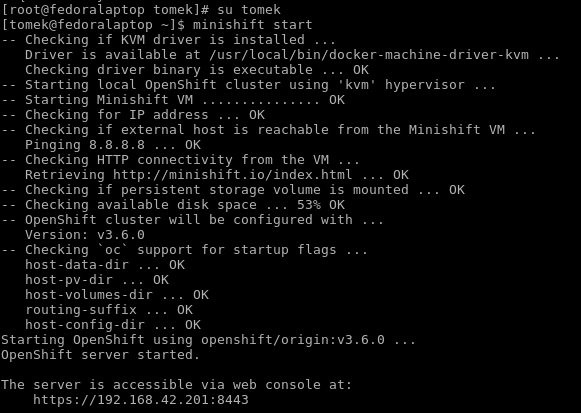
After minishift has started, you can access it using the provided address in the startup log. The first screen is a login screen. On this screen, you can use any credentials (as Minishift is a test tool) and click the Login button. After you do this, you will see the web console, which is one way of managing the OpenShift cluster.
Web console
A web console is a graphical tool that enables you to view and manage the content of an OpenShift project. From a technical point of view, the console is a graphical interface that provides convenient abstraction over the OpenShift REST API, which it uses to modify the cluster model according to user operations.
Here’s the main console window:
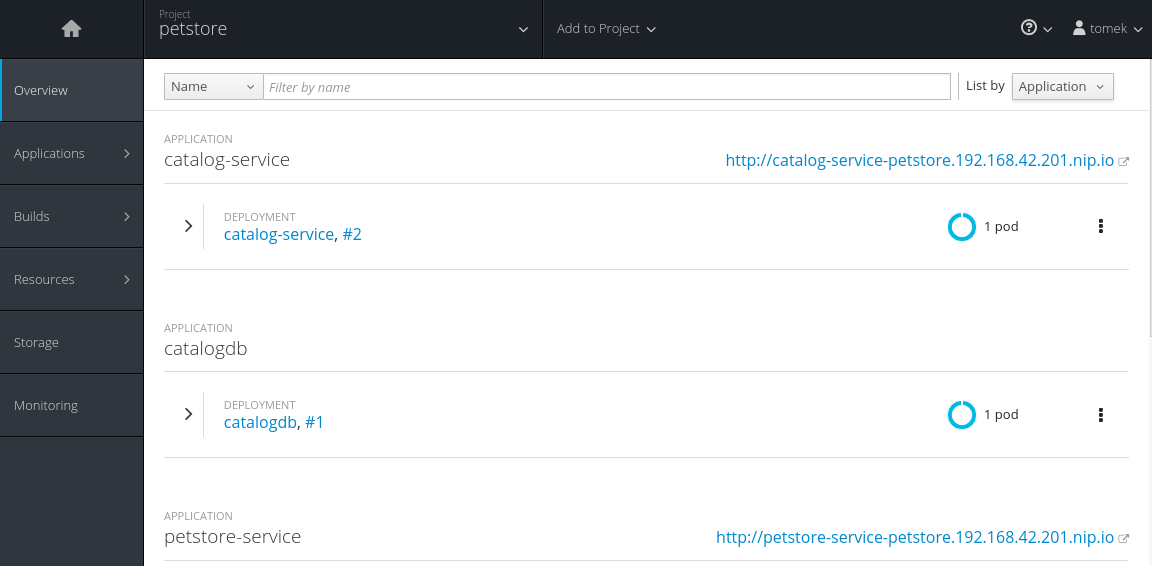
As you can see in the preceding screenshot, the console allows you to manage projects, view their content, and modify it. The overview (presented in the preceding screenshot) contains an application deployed in the petstore namespace. The menu on the left allows you to view and modify different aspects of the cluster, such as builds, deployments, or persistent resources.
YAML notation
Although the majority of configuration can be done using the graphical interface, sometimes it will be necessary to edit the internal representation of OpenShift objects.
Each object in an OpenShift model can be represented using this kind of notation. If you click on Applications | Deployments, choose one of them, click on Actions in the top-right corner. You will be able to choose the Edit YAML option. This applies to all objects in the console.
CLI
Sometimes, it is more convenient to use a command-line tool instead of graphical interface. OpenShift provides it too. The OpenShift CLI implements the oc command-line tool, which allows for managing the cluster from the terminal.
The first thing that you have to do in order to use oc is to log in to the cluster, as follows:
oc loginYou will be asked for your credentials, and will have to provide the same credentials that were used to create your project in the web console.
There are a number of operations that the oc tool provides.
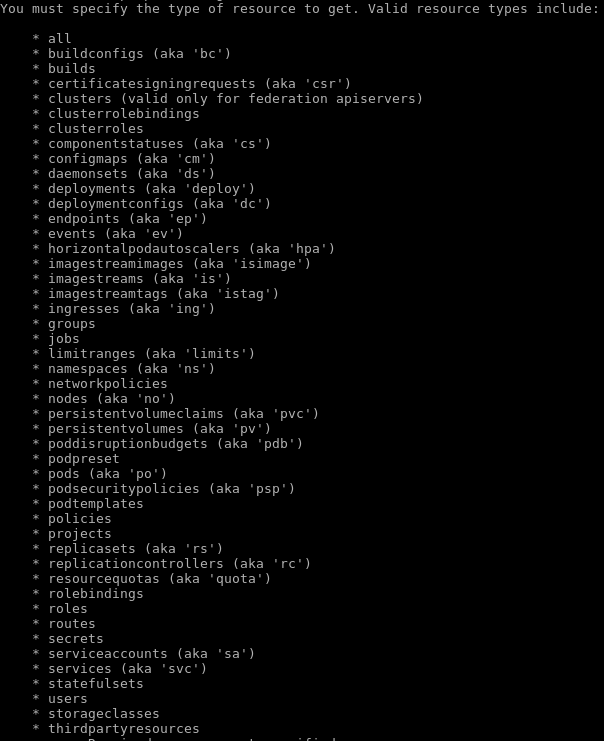
The get operation allows you to obtain available information about the availability of a given type of object. Here’s how you can invoke the command:
oc getThe tool will suggest a type of object that you can inspect; take a look:
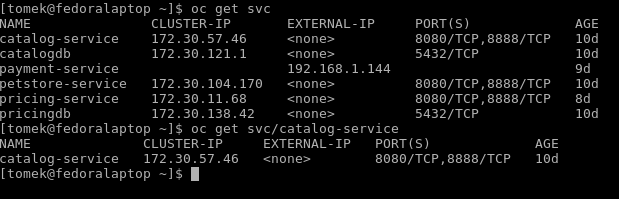
You can use the oc get command to inspect the services available in the cluster:
You can also take advantage of labels. If you write:
oc get all -l app=catalog-serviceThen you will be able to see all kinds of objects associated with the service.
As you can see in the preceding code, you can list the objects that you are interested in using the get command. If you want to get some more information about them, you need to use the oc describe command, as follows:
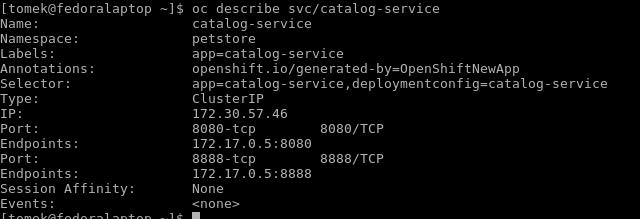
The describe command allows you to read all the information about the given type of object.