Introduction to NLP Tokenization
Tokenization is the process of breaking down text into smaller units called tokens. A token can be a word, sentence, or even a subword. Tokenization is a fundamental step in Natural Language Processing (NLP) because it helps computers understand and process text efficiently.
Analogy: Imagine you are reading a book. Instead of reading the entire book at once, you read it sentence by sentence and word by word. This way, you can understand its meaning better. Similarly, computers need to break text into smaller parts to analyze it.
Types of Tokenization
Tokenization can be classified into different types based on how the text is broken down:
- Word Tokenization – Splitting text into words.
- Sentence Tokenization – Splitting text into sentences.
- Subword Tokenization – Breaking words into meaningful subwords (useful in deep learning models).
- Whitespace Tokenization – Splitting text based on spaces.
- Punctuation-based Tokenization – Splitting text based on punctuation marks.
- Regex-based Tokenization – Using patterns to extract tokens.
- Byte Pair Encoding (BPE) – Common in deep learning for handling unknown words.
1. Word Tokenization
Word tokenization splits a text into individual words. It removes spaces and sometimes punctuation marks.
Example:
Input: "Natural Language Processing is amazing!"
Word Tokens: ['Natural', 'Language', 'Processing', 'is', 'amazing', '!']The following is the Python Code using nltk for word tokenization.
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "Natural Language Processing is amazing!"
tokens = word_tokenize(text)
print(tokens) # Output: ['Natural', 'Language', 'Processing', 'is', 'amazing', '!']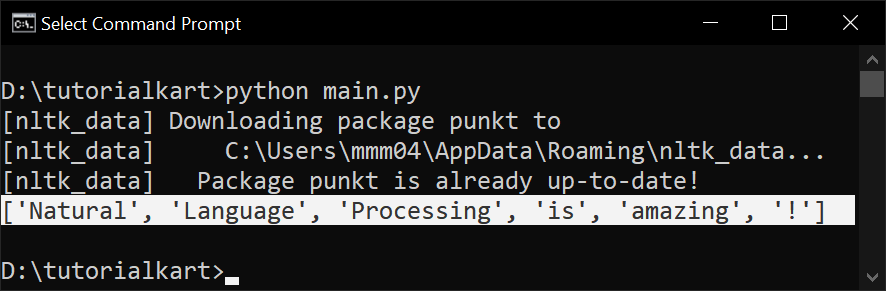
2 Sentence Tokenization
Sentence tokenization breaks text into separate sentences. This is useful when analyzing long paragraphs.
Example:
Input: "Hello world! NLP is amazing. Let's learn it together."
Sentence Tokens: ['Hello world!', 'NLP is amazing.', "Let's learn it together."]The following is the Python code using nltk for sentence tokenization.
from nltk.tokenize import sent_tokenize
text = "Hello world! NLP is amazing. Let's learn it together."
sentences = sent_tokenize(text)
print(sentences)
# Output: ['Hello world!', 'NLP is amazing.', "Let's learn it together."]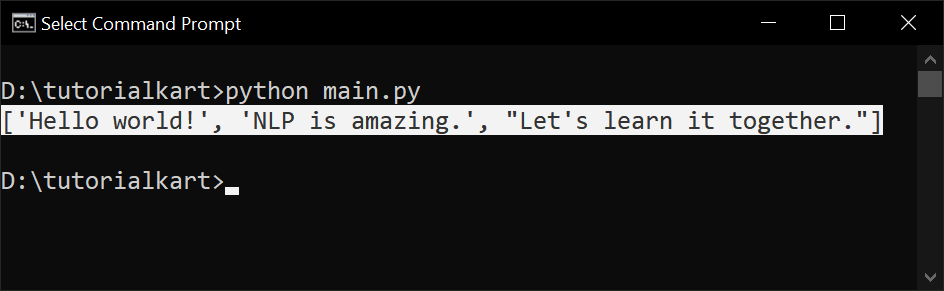
3 Subword Tokenization
Subword tokenization breaks words into smaller meaningful parts. This is helpful in languages where words are formed using multiple parts (e.g., “unhappiness” → “un”, “happiness”).
Example:
Input: "unhappiness"
Subword Tokens: ['un', 'happiness']Byte Pair Encoding (BPE): Used in deep learning models like BERT and GPT to split words into frequent subwords.
4 Whitespace Tokenization
Whitespace tokenization simply splits words based on spaces.
Example:
Input: "Tokenization is useful in NLP"
Output: ['Tokenization', 'is', 'useful', 'in', 'NLP']Python Code:
text = "Tokenization is useful in NLP"
tokens = text.split(" ")
print(tokens) # Output: ['Tokenization', 'is', 'useful', 'in', 'NLP']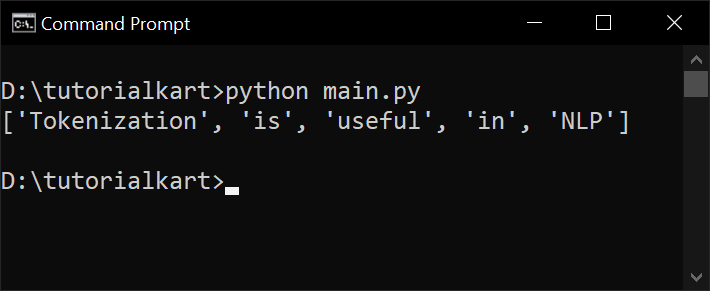
5 Punctuation-based Tokenization
Some tokenizers split text based on punctuation.
Example:
Input: "Hello, world! How are you?"
Output: ['Hello', 'world', 'How', 'are', 'you']Python Code:
import re
text = "Hello, world! How are you?"
tokens = re.findall(r'\b\w+\b', text)
print(tokens) # Output: ['Hello', 'world', 'How', 'are', 'you']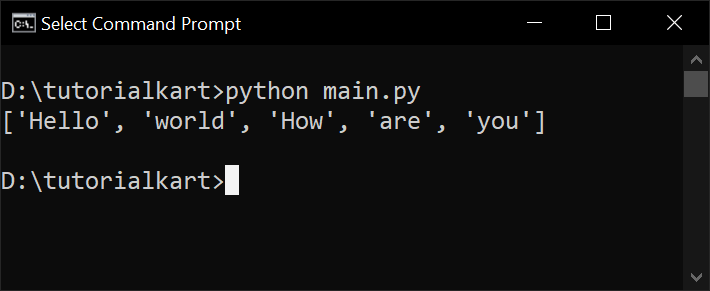
6 Regex-based Tokenization
Regular Expressions (regex) can be used to extract specific patterns from text.
Example: Extracting words that start with a capital letter.
import re
text = "John and Mary went to New York."
tokens = re.findall(r'\b[A-Z][a-z]*\b', text)
print(tokens) # Output: ['John', 'Mary', 'New', 'York']
7 Byte Pair Encoding (BPE)
Used in NLP models like GPT and BERT, BPE breaks words into frequently occurring subunits.
Example:
Input: "unhappiness"
BPE Tokens: ['un', 'happiness']Comparison of Tokenization Methods
| Method | Use Case | Example Output |
|---|---|---|
| Word Tokenization | Breaking text into words | [‘NLP’, ‘is’, ‘fun’, ‘!’] |
| Sentence Tokenization | Breaking text into sentences | [‘Hello world!’, ‘NLP is fun.’] |
| Subword Tokenization | Handling unknown words or compound words | [‘un’, ‘happiness’] |
| Whitespace Tokenization | Splitting text based on spaces | [‘Tokenization’, ‘is’, ‘useful’, ‘in’, ‘NLP’] |
| Punctuation-based Tokenization | Splitting text based on punctuation | [‘Hello’, ‘world’, ‘How’, ‘are’, ‘you’] |
| Regex Tokenization | Extracting text using custom patterns | [‘Hello’, ‘world’] (Extracting words with capital letters) |
| Byte Pair Encoding (BPE) | Used in deep learning models for handling unknown words | [‘un’, ‘happiness’] |
| SentencePiece Tokenization | Used in Transformer models for language modeling | [‘▁This’, ‘▁is’, ‘▁a’, ‘▁test’] |
| Morpheme-based Tokenization | Used for languages like Japanese or Korean | [‘食べ’, ‘ます’] |
Choosing the Right Tokenization Method for Different Scenarios
| Scenario | Best Tokenization Method | Reason |
|---|---|---|
| Text Analysis (Basic NLP Processing, Text Cleaning, Word Frequency Count, TF-IDF, Bag-of-Words models) | Word Tokenization | Word tokenization provides individual words, making it useful for counting word frequencies, vectorization, and text cleaning. |
| Text Summarization & Sentence-Level Analysis (Summarization models, Readability analysis, Document segmentation) | Sentence Tokenization | Sentence segmentation helps in structuring text and summarizing key points efficiently. |
| Machine Translation (MT) and Speech-to-Text Systems | Subword Tokenization (BPE, SentencePiece) | Helps in translating unknown words and dealing with morphological variations in languages. |
| Search Engines & Information Retrieval | Word Tokenization with Stop-word Removal | Reduces noise in search queries and improves keyword-based search results. |
| Sentiment Analysis & Opinion Mining | Word Tokenization + Lemmatization | Helps in identifying the sentiment of words while ensuring correct root forms are used. |
| Named Entity Recognition (NER) | Word Tokenization + Regex Tokenization | Helps extract specific patterns like names, dates, and locations efficiently. |
| Social Media Text Processing (Tweets, Hashtags, Mentions) | Regex Tokenization | Extracts specific elements like hashtags (#NLP), mentions (@user), and links. |
| Deep Learning NLP Models (BERT, GPT, Transformer Models) | Subword Tokenization (BPE, WordPiece, SentencePiece) | Optimizes vocabulary size while preserving meaning in transformer-based models. |
| Languages with Complex Morphology (Japanese, Korean, Arabic) | Morpheme-based Tokenization | Handles languages where words have multiple morphemes that need separate processing. |
| Parsing & Grammar Analysis | Punctuation-based Tokenization | Helps in analyzing sentence structures while preserving punctuation. |
Conclusion
Tokenization is a crucial step in NLP that helps computers process text efficiently. There are different types of tokenization methods suited for various applications.
Key Takeaways:
- Word and sentence tokenization are widely used in NLP.
- Subword tokenization is helpful for deep learning models.
- Regex tokenization allows for custom text extraction.
Next Topics:
- Stop-word Removal
- Stemming and Lemmatization
- POS Tagging