Apache Hadoop MapReduce 1.0 is the original processing framework used in Hadoop 1.x to run distributed batch jobs on data stored in HDFS. It follows the Map, Shuffle, and Reduce pattern, where large input data is split, processed in parallel, grouped by key, and then aggregated into final output.
In Hadoop 1.x, MapReduce is not only the programming model. It also provides the execution layer that schedules and monitors jobs through the JobTracker and TaskTrackers. In Hadoop 2.x and later, YARN separates resource management from processing, so MapReduce becomes one processing engine that can run on YARN instead of controlling the whole cluster by itself.
What MapReduce 1.0 Means in Apache Hadoop
MapReduce 1.0 is the first-generation Hadoop processing architecture. It is designed for batch processing, where the input data is already available, the job runs across a cluster, and the final result is written back to storage, usually HDFS.
The programming model works with key-value pairs. The mapper reads input records and emits intermediate key-value pairs. Hadoop groups values that belong to the same key. The reducer receives each key with its collection of values and produces the final result.
A simple example is word count. The mapper emits each word with the value 1. The shuffle phase groups all values for the same word. The reducer adds the values and writes the total count for every word.
MapReduce 1.0 Job Flow: Input, Map, Shuffle, Reduce, Output
A Hadoop MapReduce job normally moves through these stages:
- Input split creation: Hadoop divides the input files into logical splits so that map tasks can process them in parallel.
- Record reading: An input format reads each split and converts records into input key-value pairs.
- Map phase: Mapper code transforms input records into intermediate key-value pairs.
- Optional combiner phase: A combiner may perform local aggregation before data is transferred across the network.
- Partition and shuffle phase: Hadoop decides which reducer receives each key and transfers mapper output to reducers.
- Sort and group phase: Values are grouped by key before they are passed to reducer code.
- Reduce phase: Reducer code aggregates or transforms grouped values.
- Output writing: The final key-value pairs are written to the configured output path.
Map Phase in Hadoop MapReduce 1.0
Mapping means converting raw input records into intermediate <key, value> pairs based on the problem statement.
Input to Mapper: raw records represented as key-value pairs by the input format
Output from Mapper: intermediate <key, value> pairs
For example, in a word count job, the mapper reads a line of text and emits each word as the key and 1 as the value.
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\\s+");
for (String word : words) {
if (!word.isEmpty()) {
context.write(new Text(word), new IntWritable(1));
}
}
}This is only the mapper logic. A complete Hadoop job also needs the reducer, job configuration, input path, and output path.
Shuffle and Sort Phase in MapReduce 1.0
Shuffle is the movement and grouping of mapper output before it reaches the reducer. Hadoop partitions mapper output, transfers it to the correct reducer, sorts it by key, and groups all values that belong to the same key.
Input to Shuffle: intermediate <key, value> pairs from map tasks
Output from Shuffle: grouped data in the form <key, list(values)> for each reducer
The programmer usually does not write shuffle code. Hadoop handles shuffle and sort automatically. A developer may customize related behavior by using a partitioner, combiner, grouping comparator, or sort comparator when the job requires it.
Reduce Phase in Hadoop MapReduce 1.0
Reducing means processing each key with all of its grouped values and producing the final output for that key.
Input to Reducer: <key, list(values)>
Output from Reducer: final <key, value> pairs written to the output path
In a word count program, the reducer receives a word and a list of values such as [1, 1, 1]. It adds the values and writes the total count for that word.
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int total = 0;
for (IntWritable value : values) {
total += value.get();
}
context.write(key, new IntWritable(total));
}A typical reducer output for the word count example may look like this:
hadoop 4
mapreduce 3
hdfs 2Stages in a Hadoop MapReduce 1.0 Job
The following diagram shows typical stages in a Hadoop MapReduce job and the data flow from one stage to another:
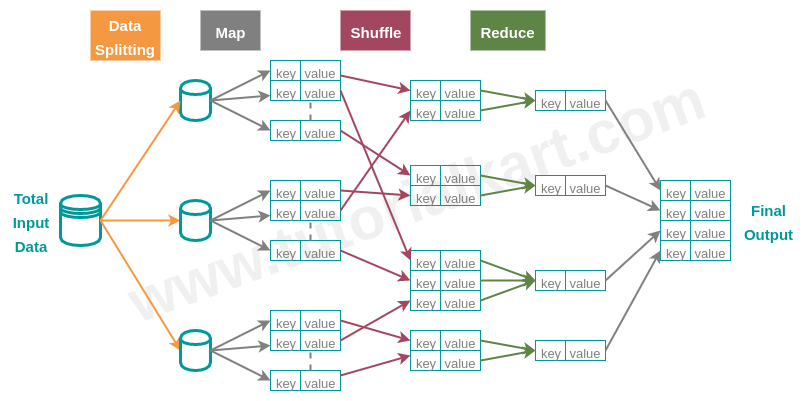
MapReduce 1.0 Architecture: JobTracker and TaskTrackers
In Hadoop 1.x, MapReduce 1.0 uses a master-worker architecture for job execution.
- JobTracker: The central service that accepts jobs, divides them into tasks, schedules tasks on cluster nodes, monitors progress, and handles failed task attempts.
- TaskTracker: The worker service running on each data node or worker node. It launches map and reduce task attempts and reports status back to the JobTracker.
- Task slots: Hadoop 1.x uses configured map slots and reduce slots on TaskTracker nodes. These slots limit how many map and reduce tasks can run at the same time.
This architecture is simple to understand, but it has limitations. The JobTracker is responsible for both resource management and job coordination, so very large clusters can put heavy pressure on one central service. Hadoop 2.x introduced YARN to separate resource management from application execution.
What Hadoop Developers Implement in a MapReduce 1.0 Program
For most MapReduce jobs, the programmer mainly writes the mapper and reducer logic. Hadoop handles input splitting, task scheduling, shuffle, sort, grouping, retry attempts, and output writing based on the job configuration.
As a Hadoop developer, the main design work is to decide how the input should be represented as keys and values, what the mapper should emit, how keys should be grouped, and how the reducer should aggregate or transform the grouped values.
| MapReduce part | Usually written by developer? | Purpose in Hadoop 1.x job |
|---|---|---|
| Mapper | Yes | Transforms input records into intermediate key-value pairs. |
| Reducer | Usually yes | Aggregates or processes grouped values for each key. |
| Driver or job configuration | Yes | Sets mapper, reducer, input path, output path, key classes, value classes, and job options. |
| Combiner | Optional | Performs safe local aggregation before shuffle to reduce network transfer. |
| Partitioner | Optional | Controls which reducer receives each key. |
| Shuffle and sort | No, unless customized | Moves, sorts, and groups mapper output before reducer execution. |
MapReduce 1.0 Example: Word Count Data Flow
The word count problem is a useful way to understand the MapReduce data flow.
Input line:
Hadoop MapReduce HadoopThe mapper emits one pair for each word:
(Hadoop, 1)
(MapReduce, 1)
(Hadoop, 1)During shuffle and sort, Hadoop groups values by key:
(Hadoop, [1, 1])
(MapReduce, [1])The reducer adds the values and writes the final result:
Hadoop 2
MapReduce 1MapReduce 1.0 Compared with MapReduce on YARN
MapReduce 1.0 and MapReduce on YARN use the same basic Map and Reduce programming idea, but the cluster execution architecture is different.
| Area | MapReduce 1.0 in Hadoop 1.x | MapReduce on YARN in Hadoop 2.x and later |
|---|---|---|
| Resource management | Handled by JobTracker | Handled by YARN ResourceManager and NodeManagers |
| Job coordination | Handled by JobTracker | Handled by an ApplicationMaster for the job |
| Worker process | TaskTracker | NodeManager with containers |
| Cluster model | Mainly built around MapReduce jobs | Can run different distributed processing frameworks |
| Common limitation addressed | JobTracker becomes responsible for too much work at scale | Resource management is separated from application execution |
For learning Hadoop fundamentals, MapReduce 1.0 is still useful because it explains the original model clearly: split the data, map records, shuffle by key, reduce grouped values, and write output. For modern Hadoop clusters, YARN-based execution is the standard architecture to understand next.
When MapReduce 1.0 Works Well and When It Does Not
MapReduce 1.0 is suitable for large batch workloads where the same operation must be applied to many records. It works well for jobs such as log processing, indexing, large-scale counting, joins that can be expressed as key grouping, and offline aggregation.
It is not a good fit for low-latency queries, interactive analytics, graph algorithms that need many repeated iterations, or streaming workloads where results must be produced continuously. MapReduce writes intermediate and final data through disk-heavy stages, so repeated iterative processing can become inefficient.
Common Mistakes While Learning Hadoop MapReduce 1.0
- Thinking that shuffle is optional: Shuffle and sort are core parts of the MapReduce execution flow, even when the programmer does not write shuffle code.
- Using a combiner like a reducer without checking correctness: A combiner must be safe for partial aggregation. It should not change the final result if it runs zero, one, or multiple times.
- Choosing poor keys: If most records go to one key, one reducer may receive too much data and slow down the whole job.
- Forgetting that output paths must not already exist: Hadoop jobs commonly fail when the configured output directory already exists.
- Confusing Hadoop 1.x architecture with YARN: MapReduce 1.0 uses JobTracker and TaskTrackers, while Hadoop 2.x and later use YARN services for resource management.
MapReduce 1.0 FAQ
What is MapReduce 1.0 in Hadoop?
MapReduce 1.0 is the original Hadoop 1.x processing framework for distributed batch jobs. It uses map tasks, shuffle and sort, and reduce tasks to process large data sets stored across a Hadoop cluster.
What are the main phases of a MapReduce 1.0 job?
The main phases are input splitting, record reading, map, optional combine, partition, shuffle, sort, reduce, and output writing. The most visible programming phases are Map and Reduce, while Hadoop manages shuffle and sort automatically.
What is the role of JobTracker in MapReduce 1.0?
The JobTracker accepts MapReduce jobs, schedules map and reduce tasks, tracks task progress, and handles failed task attempts. In Hadoop 1.x, it also plays a central role in resource management.
How is MapReduce 1.0 different from YARN-based MapReduce?
MapReduce 1.0 uses JobTracker and TaskTrackers. YARN-based MapReduce separates resource management into YARN services, allowing Hadoop clusters to run MapReduce and other distributed processing frameworks more flexibly.
Does a Hadoop developer need to write shuffle code in MapReduce 1.0?
Usually no. Hadoop performs shuffle, sort, and grouping automatically. Developers mainly write mapper, reducer, and job configuration code, and customize partitioning or sorting only when the job requires it.
Editorial QA Checklist for This MapReduce 1.0 Tutorial
- Confirm that MapReduce 1.0 is described as the Hadoop 1.x processing architecture with JobTracker and TaskTrackers.
- Check that the Map, Shuffle, and Reduce phases are explained using key-value pairs.
- Verify that YARN is described only as the Hadoop 2.x and later resource-management architecture, not as part of MapReduce 1.0.
- Ensure code examples use Hadoop-style mapper and reducer logic and are not presented as a complete runnable project.
- Review whether the word count example clearly shows mapper output, grouped shuffle output, and reducer output.
MapReduce 1.0 Key Takeaways in Apache Hadoop
MapReduce 1.0 is the original batch processing API and execution architecture of Hadoop 1.x. It processes data as key-value pairs through Map, Shuffle and Sort, and Reduce phases. The developer usually writes mapper, reducer, and job configuration code, while Hadoop manages task scheduling, data movement, sorting, grouping, retries, and output writing.
In this Apache Hadoop Tutorial, we learned how MapReduce 1.0 works, how mapper and reducer logic fit into the job flow, why shuffle and sort are important, and how the Hadoop 1.x JobTracker and TaskTracker architecture differs from YARN-based Hadoop processing.