Decision Tree in Machine Learning
Decision Tree in Machine Learning is a supervised learning algorithm used for both classification and regression. It learns a sequence of feature-based questions from training data and uses those questions to predict the class label or numerical value for a new record.
A decision tree is easy to understand because its prediction path looks similar to human decision-making: start at the root, test a condition, move through branches, and stop at a leaf node where the final prediction is made. Decision trees can capture non-linear patterns and interactions between features without requiring the input data to follow a straight-line relationship.
What is a Decision Tree in Machine Learning?
A decision tree is a tree-shaped model in which each internal node represents a test on a feature, each branch represents the result of that test, and each leaf node represents the predicted output. For a classification problem, the output is a category such as human, bird, or plant. For a regression problem, the output is a number such as price, temperature, or demand.
Wondering what a Decision Tree would be ? You might have come across the programmatic representation of a decision tree which is a nested if-else.
Let us consider the following pseudo logic, where we are trying to classify the given living-thing into either human, bird or plant :
if(displacement is present){
if(wings are present AND feathers are present){
living-thing is bird
} else if(hands are present){
living-thing is human
}
} else if(displacement is absent){
living-thing is plant
}In the above pseudo code,
Output variable is category of living-thing whose value could be human or bird or plant.
Input variable is living-thing
Features of input data taken into consideration are displacement[whose values are present/absent], wings[whose values are present/absent], feathers[whose values are present/absent] and hands[whose values are present/absent]. So we have four features whose values are discrete.
Decision Tree Terminology: Root Node, Branches and Leaf Nodes
The main parts of a decision tree are:
- Root node: the first decision point in the tree. It uses the feature that gives the most useful split according to the selected splitting criterion.
- Decision node: an internal node where another feature condition is tested.
- Branch: the path followed after a condition is evaluated.
- Leaf node: the final node that gives the predicted class or value.
- Depth: the length of the longest path from the root node to a leaf node.
For the living-thing example, the first useful question may be whether displacement is present. If displacement is absent, the prediction can be plant. If displacement is present, another question such as whether wings are present can help decide between bird and human.
Why Decision Trees are Needed in Machine Learning
In the traditional programs, the above if-else-if code is hand written. Efforts put by a human being in identifying the rules and writing this piece of code where there are four features and one input are relatively less.
But could you imagine the efforts required if the number of features are in hundreds or thousands. Its becomes a tedious job with nearly impossible timelines. Decision Tree could learn these rules from the training data. Despite other classifiers like Naive Bayes Classifier or other linear classifiers, Decision Tree could capture the non-linearity of a feature or any relation between two or more features.
Mentioning about capturing relation among features, in the above example, the features : wings and feathers are co-related. For the considered example(or data set), their values are related in a way such that their collective value is deciding on the decision flow.
Decision trees are also useful because they do not require feature scaling in the same way as distance-based algorithms. A tree compares values through thresholds or categories, so changing a feature from metres to centimetres does not change the logical ordering of that feature. However, clean data and meaningful features are still important for good predictions.
Decision Tree Example Dataset for Classification
In machine learning, input dataset for the Decision Tree algorithm would be the list of feature values with the corresponding categorical value. A sample of the dataset as shown in the below table :
| Input | Output | Features | Features | Features | Features |
|---|---|---|---|---|---|
| living-being | category | wings | hands | feathers | displacement |
| Joe | human | absent | present | absent | present |
| Parrot | bird | present | absent | present | present |
| Jean | human | absent | present | absent | present |
| Hibiscus | plant | absent | absent | absent | absent |
| Eagle | bird | present | absent | present | present |
| Rose | plant | absent | absent | absent | absent |
Each row in the above table represents an observation/experiment.
In practical scenarios, the number of features could be from single digit number to thousands, and the data set would contain single digit number to millions of entries/observations/experiments.
The target column in this example is category. The feature columns are wings, hands, feathers, and displacement. During training, the decision tree algorithm tries to find which feature condition separates the classes most clearly.
How a Decision Tree is Built from Training Data
The common way to build a Decision Tree is to use a greedy approach. Consider you are greedy on the number of Decision Nodes. The number of Decision Nodes should be minimal. By testing a feature value, the Dataset is broken into sub-Datasets, with a condition that the split gives maximum benefit to the classification i.e., the feature value considered(among all the possible feature value combinations) is the best available to categorize the given data set into two subsets. In each sub-Dataset, a new feature value combination is chosen, as in the former split, to divide it into smaller sub-Datasets, with the same condition that the split gives maximum benefit to the classification. The process is repeated until a Decision Node is not required to further split the sub-Dataset, and almost all of the samples in that sub-Dataset belong to a single category.
Please refer to Greedy Algorithm for more insight.
In classification, the algorithm usually chooses splits that reduce class mixing. A node is considered purer when most records in that node belong to the same class. Common splitting measures include Gini impurity and entropy. Both are ways to measure how mixed the classes are at a node.
Gini impurity for a decision tree split
For a node with class proportions p1, p2, …, pk, Gini impurity is:
Gini = 1 - (p1^2 + p2^2 + ... + pk^2)If all records at a node belong to one class, one class proportion is 1 and the rest are 0. In that case, Gini impurity becomes 0, meaning the node is pure.
Entropy and information gain in a decision tree
Entropy is another impurity measure. For a classification node, entropy is commonly written as:
Entropy = - Σ pi log2(pi)A split is useful when it reduces entropy. The reduction in entropy after splitting is called information gain. A higher information gain means the split has separated the classes better.
Flowchart Representation of a Decision Tree
The graphical representation of Decision Tree for the Dataset mentioned above would be as shown in the following diagram :
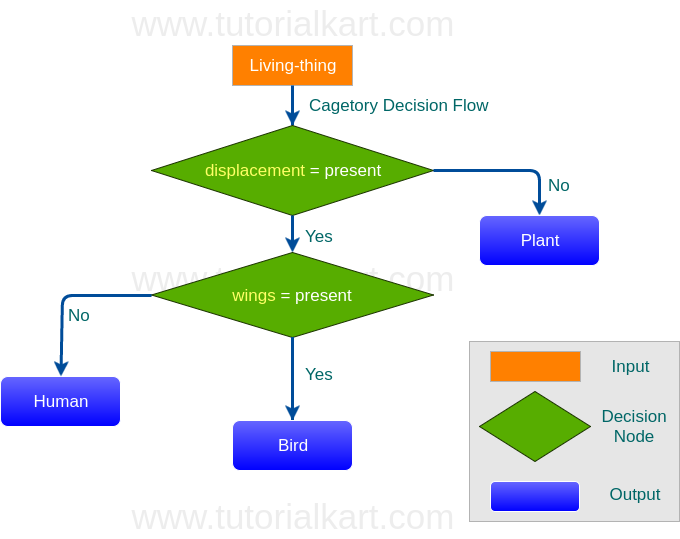
From the above flowchart, it is evident that the Decision Tree has made use of only two features [displacement, wings] as the other two features are redundant. Thus reducing the number of Decision Nodes.
The decision path for each record can be read directly from the tree. For example, if displacement is absent, the prediction is plant. If displacement is present and wings are present, the prediction is bird. If displacement is present and wings are absent, the prediction is human for this simple dataset.
Decision Tree Classification vs Decision Tree Regression
A decision tree can solve two common supervised learning tasks:
| Task | Target value | Example prediction | Typical split objective |
|---|---|---|---|
| Classification | Category or class label | bird, human, plant | Reduce class impurity using Gini impurity or entropy |
| Regression | Continuous numerical value | house price, sales amount, temperature | Reduce prediction error such as mean squared error |
In a classification tree, a leaf node usually predicts the majority class of the training records that reached that leaf. In a regression tree, a leaf node usually predicts an average or similar summary value of the training records that reached that leaf.
Decision Tree Algorithm Steps
A simplified training process for a decision tree classifier is:
- Start with the full training dataset at the root node.
- Evaluate possible feature conditions that can split the dataset.
- Select the split that gives the best improvement according to the chosen criterion.
- Create child nodes using that split.
- Repeat the same process on each child node.
- Stop splitting when a stopping condition is met, such as pure nodes, maximum depth, minimum samples, or no useful improvement.
- Use the final leaf nodes to make predictions on new data.
This process is greedy because the algorithm chooses the best split at the current node. It does not test every possible complete tree, because that would be too expensive for most real datasets.
Small Python Example of a Decision Tree Classifier
The following example shows the same idea using simple binary feature values. Here, 1 means present and 0 means absent. The feature order is wings, hands, feathers, and displacement.
from sklearn.tree import DecisionTreeClassifier
# Features: [wings, hands, feathers, displacement]
X = [
[0, 1, 0, 1], # Joe
[1, 0, 1, 1], # Parrot
[0, 1, 0, 1], # Jean
[0, 0, 0, 0], # Hibiscus
[1, 0, 1, 1], # Eagle
[0, 0, 0, 0], # Rose
]
y = ["human", "bird", "human", "plant", "bird", "plant"]
model = DecisionTreeClassifier(random_state=0)
model.fit(X, y)
# New sample: wings absent, hands present, feathers absent, displacement present
prediction = model.predict([[0, 1, 0, 1]])
print(prediction[0])humanThis example is intentionally small so that the decision path is easy to follow. Real datasets need train-test splitting, evaluation metrics, handling of missing values, and model tuning before the model can be trusted.
Advantages of Decision Trees in Machine Learning
- Easy to interpret: the path from root to leaf can be read as a set of rules.
- Works with non-linear relationships: a decision tree can split the feature space into separate regions.
- Handles feature interactions: one feature can be tested after another, allowing combined conditions.
- Useful for classification and regression: the same tree structure can be adapted to different target types.
- Minimal feature scaling requirement: decision trees do not usually need standardisation or normalisation of numerical features.
Limitations of Decision Trees and Overfitting
Decision trees can overfit when they grow too deep and learn noise from the training data instead of general patterns. An overfitted tree may perform well on the training dataset but poorly on new data.
Common ways to reduce overfitting include:
- limiting the maximum depth of the tree,
- requiring a minimum number of samples before a node can be split,
- requiring a minimum number of samples at each leaf node,
- pruning branches that do not improve validation performance, and
- using ensemble methods such as random forests or gradient boosted trees.
Decision trees can also be sensitive to small changes in the training data. A slightly different dataset may produce a different tree structure. This is one reason why ensembles such as random forests are often used for better stability.
Decision Tree Use Cases in Machine Learning
Decision trees are used when a supervised learning problem requires interpretable rules or a baseline model that can handle non-linear patterns. Common examples include:
- customer churn classification,
- loan approval risk classification,
- medical screening support models,
- spam or non-spam classification,
- product recommendation rules, and
- house price or demand prediction using regression trees.
For sensitive domains such as healthcare, finance, and legal decision support, a decision tree should not be used without proper validation, bias checks, and expert review. Interpretability helps, but it does not automatically make a model accurate or fair.
Decision Tree Model Evaluation Checklist
- Check train-test performance: compare training accuracy with test accuracy to detect possible overfitting.
- Inspect tree depth: a very deep tree may be memorising training records.
- Review important splits: confirm that the top features make domain sense.
- Handle missing values: decide how missing feature values are cleaned or encoded before training.
- Evaluate the right metric: use accuracy, precision, recall, F1-score, ROC-AUC, mean absolute error, or mean squared error depending on the problem.
- Test on new data: a decision tree is useful only if it generalises beyond the training records.
Decision Tree Frequently Asked Questions
Is a decision tree used only for classification?
No. A decision tree can be used for classification and regression. Classification trees predict class labels, while regression trees predict numerical values.
Why is a decision tree called an interpretable model?
A decision tree is called interpretable because its prediction can be traced through a visible path of feature conditions from the root node to a leaf node.
What is overfitting in a decision tree?
Overfitting happens when a decision tree learns very specific patterns or noise from the training dataset and fails to perform well on unseen data.
Does a decision tree need feature scaling?
Usually, no. A decision tree makes splits using feature conditions and thresholds, so standard scaling is not normally required. Data cleaning and correct encoding are still important.
How is a decision tree related to a random forest?
A random forest builds many decision trees and combines their predictions. This often reduces the instability and overfitting risk of a single decision tree.
Conclusion: Decision Tree in Machine Learning
In this Machine Learning tutorial, we have seen what is a Decision Tree in Machine Learning, what is the need of it in Machine Learning, how it is built and an example of it. Decision Tree is a building block in Random Forest Algorithm where some of the disadvantages of Decision Tree are overcome.
A decision tree is useful when you need a model that can learn feature-based rules and explain predictions in a readable structure. For practical machine learning, it should be evaluated on unseen data and tuned carefully to avoid overfitting.