Random Forest in Machine Learning
Random Forest in Machine Learning is an ensemble learning algorithm that builds many decision trees and combines their predictions. It can be used for classification, where the output is a category, and regression, where the output is a numeric value.
A random forest is useful when a single decision tree is too sensitive to the training data. Instead of depending on one tree, the algorithm trains several trees on different samples of the data and different subsets of features. The final prediction is made by combining the results of all trees.
Random forest is opted for tasks that include generating multiple decision trees during training and considering the outcome of polls of these decision trees, for an experiment/data-point, as prediction.
Random Forest Definition for Classification and Regression
Random Decision Forest, or Random Forest, is a group of decision trees. A decision tree is the base learner in a random forest. Each tree learns patterns from a training sample, and the forest combines the predictions from all trees.
- For classification, the trees vote for a class label, and the class with the highest number of votes is usually selected.
- For regression, the numeric predictions from all trees are usually averaged.
A decision tree can overfit the training data if it grows too deeply or follows noise in the dataset. Random forest reduces this risk by combining many trees that are intentionally made different from one another. This makes the final model more stable than a single decision tree in many practical machine learning problems.
A model of Random forest comprises of the following:
- Decision trees that are grown using training data
- Features recognized/used for the modeling of the data
- Rules learned by each decision tree from its own training sample
- A voting or averaging method to combine tree predictions
To make a note, Random Forests(tm) is a trademark of Leo Breiman and Adele Cutler with the official site https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
How Random Forest Builds Many Decision Trees
Random forest trains each decision tree with two important sources of randomness: random sampling of training rows and random selection of features while splitting nodes. These two steps help the trees learn different patterns instead of becoming copies of one another.
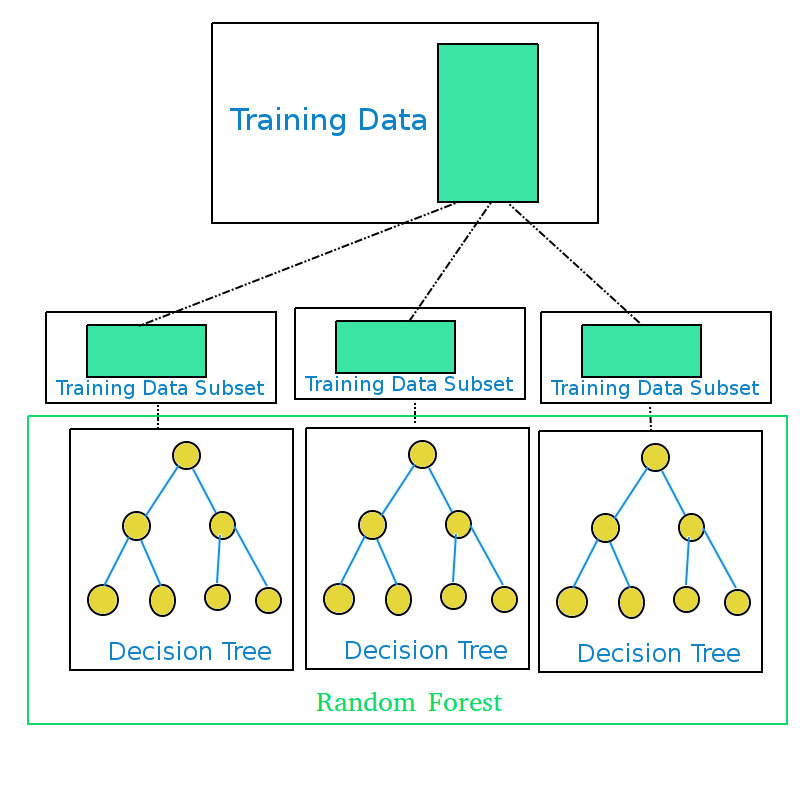
- Get the training data
- Split the training data into subsets randomly. (Number of subsets should be equal to the number of decision trees to be grown)
- Generate a decision tree for each training data subset.
- Ensemble of the decision trees generated is the Random Forest.
In a standard random forest, the random subset of rows is usually created using bootstrap sampling. This means each tree receives a sample drawn from the training data with replacement. While growing a tree, the algorithm also considers only a random subset of features at each split. This feature randomness is one of the main differences between random forest and a simple bagged group of decision trees.
Random Forest Training Data and Feature Vectors
Training data for a random forest is a collection of examples. Each example has input features and, in supervised learning, a known target value. The target may be a class label for classification or a number for regression.
Training data is an array of vectors in the N-dimension space. Each dimension in the space corresponds to a feature that you have recognized from the data, wherefore there are N features that you have recognized from the nature of data to model. In other words, each vector is composed of multiple unit vectors, not necessarily all the independent unit vectors. And, each unit vector corresponds to a feature.
| Training example | Feature vector | Target used for learning |
|---|---|---|
| Example 1 | x1 = [f1, f2, f3, …, fN] | y1 |
| Example 2 | x2 = [f1, f2, f3, …, fN] | y2 |
| Example M | xM = [f1, f2, f3, …, fN] | yM |
Here, x is the feature vector, fi is a feature value, and y is the known output used during training. For a classification problem, y may be a category such as approved or rejected. For a regression problem, y may be a value such as price, temperature, or demand.
Random Forest Prediction for a New Data Point
The problem instance which is a N-dimensional feature vector, similar to feature vectors that are used for training. It is important that the feature vector that has come for prediction also contain all the feature values as that of in training.
| xnew = [f1, f2, f3, …, fN] |
Sometimes, the data point may not have some of the features, in that case their value is zero. In practice, missing values must be handled carefully. Depending on the dataset and tool used, missing values may be imputed, encoded as a separate category, or handled by a model-specific missing-value strategy.
- In a classification random forest, each tree predicts a class, and the majority vote becomes the final class.
- In a regression random forest, each tree predicts a number, and the average of tree outputs becomes the final prediction.
Feature Correlations and Non-Linearity in Random Forest
Random forest can model non-linear relationships because each decision tree makes branch-specific splits. A tree can first split on one feature, then split on another feature inside that branch, and continue this process. This allows the model to represent interactions between features.
When fitting the model for the responses of a non-linear machine and the features selected, Random forest handles non-linearity by performing branch specific splits. When a split happens at an i-th branch, it is meant that a combination/interaction of i independent features is considered already, which is the feature interaction.
For example, a model may learn that income alone is not enough for a prediction, age alone is not enough, but a particular range of income combined with a particular age group changes the output. A tree can represent such conditional rules naturally, and a forest combines many such rules from many trees.
Random Forest Algorithm Steps in Machine Learning
- Prepare the dataset with input features and target values.
- Create many bootstrap samples from the training dataset.
- Train one decision tree on each bootstrap sample.
- At each split in a tree, consider only a random subset of features.
- Grow each tree according to the selected stopping rules such as maximum depth or minimum samples per leaf.
- For prediction, send the new feature vector through every tree.
- Combine all tree outputs using majority vote for classification or averaging for regression.
Random Forest Classification Example in Python
The following small example shows how a random forest classifier can be trained using scikit-learn. The dataset is intentionally simple so that the focus stays on the algorithm workflow.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X = [
[22, 25000],
[25, 32000],
[47, 90000],
[52, 110000],
[46, 85000],
[23, 28000]
]
y = ["low", "low", "high", "high", "high", "low"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42
)
model = RandomForestClassifier(
n_estimators=100,
random_state=42
)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(predictions)
print("Accuracy:", accuracy_score(y_test, predictions))In real projects, the dataset should be larger, cleaned properly, split carefully, and evaluated using suitable metrics such as accuracy, precision, recall, F1-score, mean absolute error, or root mean squared error depending on the task.
Important Random Forest Hyperparameters
| Hyperparameter | Meaning in random forest | Typical effect |
|---|---|---|
| n_estimators | Number of trees in the forest | More trees can improve stability but increase training and prediction time |
| max_depth | Maximum depth of each decision tree | Controls how complex each tree can become |
| max_features | Number of features considered at each split | Adds randomness and reduces correlation between trees |
| min_samples_split | Minimum samples required to split a node | Helps prevent very small, overly specific branches |
| min_samples_leaf | Minimum samples required in a leaf node | Can make the model smoother and reduce overfitting |
| bootstrap | Whether each tree uses bootstrap samples | Enables bagging-style training and out-of-bag evaluation |
Out-of-Bag Error in Random Forest
Because each tree is trained on a bootstrap sample, some training examples are left out of that tree’s sample. These left-out examples are called out-of-bag examples for that tree. A random forest can use these out-of-bag examples to estimate model performance without needing a separate validation set in some workflows.
Out-of-bag error is not a replacement for careful testing in every project, but it is a useful built-in estimate when bootstrap sampling is used. For final evaluation, a separate test set is still preferred when reliable performance reporting is required.
Random Forest Feature Importance
Random forest can provide feature importance scores. These scores help identify which input features contributed more to the model’s decisions. Feature importance is useful for model interpretation, feature selection, and understanding the dataset.
- A high importance score means the feature was useful for reducing uncertainty in the trees.
- A low importance score means the feature may have contributed little to the model.
- Feature importance should be interpreted carefully when features are highly correlated.
Advantages of Random Forest in Machine Learning
- Works for classification and regression: The same general method can solve both types of supervised learning problems.
- Reduces overfitting compared with a single tree: Combining many trees usually gives a more stable result.
- Handles non-linear patterns: Tree branches can capture feature interactions and conditional rules.
- Works with many feature types: Random forest can be used with numeric and encoded categorical features.
- Provides feature importance: The model can help identify useful predictors.
- Needs less feature scaling: Decision-tree-based methods do not usually require standardization in the same way as distance-based models.
Limitations of Random Forest Models
- Less interpretable than one decision tree: A forest has many trees, so the complete decision process is harder to explain.
- Can be slower with many trees: Large forests need more memory and computation.
- May not extrapolate well in regression: Tree-based models usually predict within patterns seen in training data.
- Feature importance can be biased: Certain importance methods can favor variables with more possible split points.
- Not always best for sparse high-dimensional text data: Linear models or specialized methods may be more suitable in some text classification tasks.
Random Forest vs Decision Tree vs SVM
| Model | Main idea | Strength | Limitation |
|---|---|---|---|
| Decision Tree | One tree of rules built from feature splits | Easy to visualize and explain | Can overfit easily |
| Random Forest | Many decision trees combined by voting or averaging | Stable and effective for many tabular datasets | Less interpretable and heavier than one tree |
| SVM | Finds a boundary that separates classes, often using kernels | Can work well in high-dimensional spaces | Can be harder to tune and scale on large datasets |
Random forest and SVM are both machine learning algorithms, but they learn in different ways. Random forest uses many tree-based rules, while SVM focuses on separating classes with a decision boundary. The better choice depends on the dataset size, feature type, interpretability needs, and evaluation results.
When to Use Random Forest for a Machine Learning Problem
- Use random forest when the data is tabular and contains many predictive features.
- Use it when a single decision tree overfits but tree-like rules are still useful.
- Use it as a strong baseline model for classification or regression.
- Use it when feature importance is helpful for analysis.
- Avoid relying only on random forest when model explainability, very low latency, or extrapolation beyond training ranges is the main requirement.
Is Random Forest AI or Machine Learning?
Random forest is a machine learning algorithm. Since machine learning is a major part of artificial intelligence, random forest can be described as an AI technique in a broad sense. More precisely, it is a supervised machine learning algorithm used for classification and regression.
Random Forest Tutorial Summary
In this machine learning tutorial, we have learnt how a Random Forest in Machine Learning is useful, constructing a Random Forest with Decision Trees, and exploiting the relations between features.
The key idea is simple: a random forest builds many decision trees, adds randomness through row sampling and feature selection, and combines predictions to produce a more reliable result than a single tree in many supervised learning tasks.
Random Forest in Machine Learning FAQ
What is a random forest in machine learning?
A random forest is an ensemble machine learning algorithm that builds many decision trees and combines their predictions. It is used for both classification and regression problems.
Why is random forest better than a single decision tree?
A single decision tree can overfit the training data. Random forest reduces this problem by training many different trees and combining their outputs, which usually gives a more stable prediction.
Is random forest used for classification or regression?
Random forest can be used for both. In classification, the trees vote for a class. In regression, the numeric predictions from trees are usually averaged.
What is the difference between SVM and random forest?
SVM tries to find a decision boundary that separates classes, while random forest combines many decision trees. SVM can work well in high-dimensional spaces, while random forest is commonly strong on tabular datasets with non-linear feature interactions.
Does random forest need feature scaling?
Random forest usually does not require feature scaling because decision trees split data based on feature thresholds. Scaling may still be needed if random forest is part of a larger pipeline that includes other algorithms.
Editorial QA Checklist for This Random Forest Tutorial
- Does the tutorial clearly define random forest as an ensemble of decision trees?
- Are classification and regression outputs explained separately?
- Does the page explain bootstrap sampling and random feature selection, not only multiple trees?
- Is overfitting discussed in relation to a single decision tree and the forest approach?
- Are feature vectors, missing values, hyperparameters, and feature importance explained in beginner-friendly language?
- Does the FAQ answer search-intent questions such as random forest vs SVM and whether random forest is AI or machine learning?