Apache Kafka Architecture
Apache Kafka architecture is built around a distributed commit log. Applications called producers write records to Kafka topics, Kafka brokers store those records in partitions, and consumers read the records at their own pace. This design makes Kafka useful for event streaming, asynchronous processing, data pipelines, and stream processing.
The main building blocks of Kafka architecture are Producers, Consumers, Stream Processors, Connectors, Topics, Partitions, Brokers, consumer groups, offsets, and cluster metadata management. Older Kafka clusters used ZooKeeper for metadata and controller election. Current Kafka deployments commonly use KRaft mode, where Kafka manages metadata through its own controller quorum.
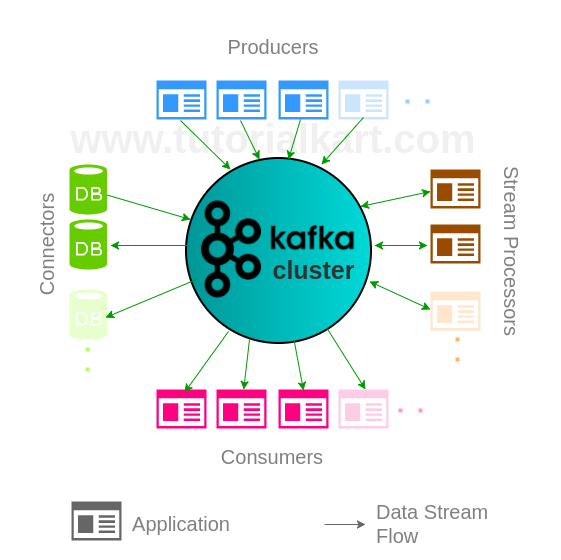
Apache Kafka architecture components at a glance
A Kafka cluster can be understood as a group of services that store, move, process, and integrate event records. The following table summarizes the role of each Kafka architecture component before we look at the record life cycle.
| Kafka component | Role in Kafka architecture |
|---|---|
| Producer | Writes records to one or more Kafka topics. |
| Topic | Named stream or category of records, such as orders, payments, or logs. |
| Partition | Ordered sequence of records inside a topic. Partitions provide scaling and parallelism. |
| Broker | Kafka server that stores topic partitions and serves producer and consumer requests. |
| Consumer | Reads records from one or more topics. |
| Consumer group | Group of consumers that share the work of reading partitions from a topic. |
| Offset | Position of a record inside a partition. Consumers track offsets to know what they have read. |
| Stream processor | Reads records, transforms or joins them, and writes results back to Kafka. |
| Connector | Moves data between Kafka and external systems such as databases, files, search engines, or cloud services. |
Life cycle of a Kafka record from producer to consumer
Now we shall see the journey of an entry through different blocks in a cluster.
A record is created by a Producer and is written to one of the existing Topics in Kafka cluster or a new Topic is created and written to it. The record in the Topic is waiting for the Consumer or Stream Processor. Consider that a Stream Processor has subscribed to the Topic. Our Entry might join some other records in the partition and read by the Stream Processor. The Processor now may transform the record into a new record or enrich it and write back to the cluster into a new Topic. There could be multiple transformations by multiple Stream Processors on the record. Now consider that after a long journey the transformed Record has come to a Topic called TheLastTopic. And also consider that a consumer has subscribed to this Topic “TheLastTopic”. Consumer consumes the record from this Topic and the record has been used up. In the journey of the record, the changes happening to the record may be logged into Relational Databases using Connectors.
In practical Kafka architecture, the record is not removed immediately when one consumer reads it. Kafka stores records for a configured retention period or retention size. Different consumer groups can read the same topic independently because each group maintains its own offsets.
Any application can become a Producer, Consumer or Stream Processor based on the role it plays in the Cluster. Kafka Cluster is flexible on how an application wants to connect to it.
Kafka Producer role in Apache Kafka architecture
Producer is an application that generates the entries or records and sends them to a Topic in Kafka Cluster.
- Producers are source of data streams in Kafka Cluster.
- Producers are scalable. Multiple producer applications could be connected to the Kafka Cluster.
- A single producer can write the records to multiple Topics [based on configuration].
- A producer chooses the target partition either by using a record key, a custom partitioner, or the default partitioning behavior.
- Producer acknowledgements decide when a write is considered successful, for example after the leader receives the record or after replicas confirm it.
Java Example for Apache Kafka Producer
Kafka Consumer and consumer group architecture
Consumer is an application that feed on the entries or records of a Topic in Kafka Cluster.
- Consumers are sink to data streams in Kafka Cluster.
- Consumers are scalable. Multiple consumer applications could be connected to the Kafka Cluster.
- A single consumer can subscribe to the records of multiple Topics [based on configuration].
- Consumers usually run inside a consumer group so that partitions can be divided among group members.
- Kafka tracks the position of consumers using offsets. This allows a consumer group to pause, restart, and continue reading from a known position.
If a topic has three partitions and a consumer group has three active consumers, Kafka can assign one partition to each consumer. If the same group has only one consumer, that consumer may read all three partitions. If a new consumer joins or leaves the group, Kafka performs a rebalance and redistributes partition ownership.
Kafka Stream Processors in event streaming architecture
Stream Processor is an application that enrich/transform/modify the entries or records of a Topic (sometimes write these modified records to a new Topic) in Kafka Cluster.
- Stream Processors first act as sink and then as source in Kafka Cluster.
- Stream Processors are scalable. Multiple Stream Processing applications could be connected to the Kafka Cluster.
- A single Stream Processor can subscribe to the records of multiple Topics [based on configuration] and then write records back to multiple Topics.
- Kafka Streams applications commonly read from input topics, perform operations such as filtering, joining, grouping, or aggregating, and write to output topics.
- Stream processing keeps intermediate data and state close to the event flow instead of waiting for a separate batch job.
Kafka Connectors for databases and external systems
Connectors are those which allow the integration of things like Relational Databases to the Kafka Cluster and automatically monitor the changes. They also help to pull those changes onto the Kafka cluster.
Connectors provide a single source of ground truth data. Which means that we have a record of changes, a Topic has undergone.
In Kafka Connect architecture, source connectors bring data from an external system into Kafka, and sink connectors move data from Kafka to another system. For example, a source connector can publish database changes to a topic, while a sink connector can write processed events to a data warehouse or search index.
Brokers, Topics and their Partitions – in Apache Kafka Architecture
Observe in the following diagram that there are three topics. Topic 0 has two partitions, Topic 1 and Topic 2 has only single partition. Topic 0 has a replication factor or 3, Topic 1 and Topic 2 have replication factor of 2. Zookeeper may elect any of these brokers as a leader for a particular Topic Partition.
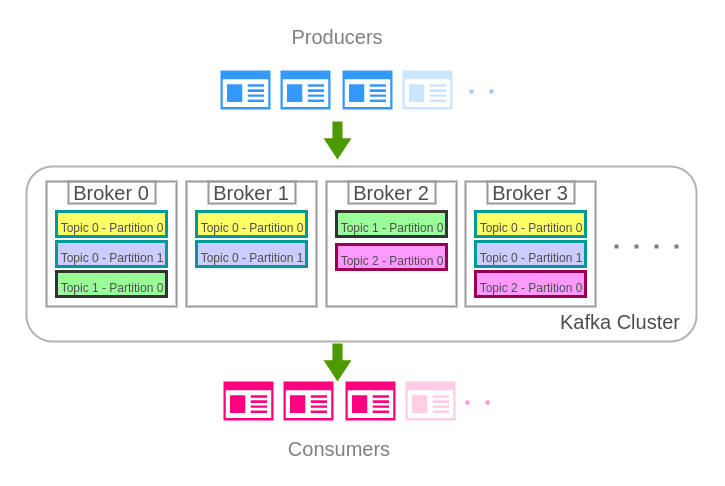
In older ZooKeeper-based Kafka clusters, ZooKeeper helped maintain cluster metadata and controller election. In current Kafka architecture, the same kind of metadata coordination is handled by Kafka controllers in KRaft mode. The basic idea remains the same for users: a partition has one leader replica that handles reads and writes, and follower replicas keep copies for fault tolerance.
Kafka Broker responsibilities in a distributed Kafka cluster
Brokers are logical separation of tasks happening in a Kafka Cluster.
- Brokers could be on multiple machines.
- Multiple brokers could be on a single machine.
- A Broker can handle some of the [partitions in] Topics and is responsible for those.
- Multiple backups of Topic Partitions are created in multiple brokers based on the number of replications you provide during the creation of a Topic.
- Brokers containing the backups of a Topic Partition help in balancing the load. [Load is the number of applications connected to the broker either for read or write operations or both.]
- If a Broker goes down, one of the Broker containing the backup partitions would be elected as a leader for the respective partitions. And thus Kafka is resilient.
- Brokers receive client requests, store records on disk, replicate partition data, and return records to consumers.
A Kafka cluster may have many brokers. Each broker has a broker id, stores one or more partition replicas, and communicates with other brokers for replication and coordination. Clients normally connect using bootstrap broker addresses and then receive metadata about the topic partitions they need to use.
Kafka Topic and partition design in Apache Kafka architecture
Topic is a logical collection of records that are assumed to fall into a certain category.
- A Topic can be created with multiple partitions by considering the load or distribution of read/write sources (producers/consumers/processors).
- Number of Partitions a Topic could be divided is provided during the creation of the Topic.
- Records inside a single partition are ordered by offset.
- Ordering across the whole topic is not guaranteed when the topic has multiple partitions.
- Partitions allow multiple consumers in a consumer group to read a topic in parallel.
When a record has a key, Kafka can use that key to route related records to the same partition. This is useful when records for the same customer, order, device, or account must be processed in order.
Kafka replication, leader partitions and fault tolerance
Replication is the mechanism that keeps copies of a partition on multiple brokers. For each partition, one replica is the leader and the other replicas are followers. Producers and consumers interact with the leader replica, while followers replicate the data from the leader.
- Leader replica: Handles reads and writes for a partition.
- Follower replica: Copies data from the leader and can become leader if needed.
- Replication factor: Number of replicas maintained for each partition.
- In-sync replicas: Replicas that are sufficiently caught up with the leader.
For a local single-broker setup, a replication factor of 1 is common. For a multi-broker Kafka cluster, replication factor must not be higher than the number of available brokers.
Kafka protocol, HTTP, TCP and REST API comparison
Kafka clients normally communicate with brokers using the Kafka protocol over TCP. Kafka is not an HTTP-based message broker in its core client-broker communication. HTTP access can be added through separate services such as a REST proxy, but that is not the same as the native Kafka protocol.
Kafka is also not a direct replacement for every REST API. REST APIs are commonly used for request-response operations such as fetching a user profile or creating an order through a service endpoint. Kafka is commonly used when systems need asynchronous event streams, durable logs, fan-out to multiple consumers, or replay of events. Many backend architectures use both: REST for direct service calls and Kafka for event-driven workflows.
Is Apache Kafka a backend system or a database?
Apache Kafka is usually part of backend infrastructure. It is not a frontend framework, and it is not usually used as a complete application backend by itself. Kafka stores records durably for a configured retention policy, but most applications still use databases for queryable application state and use Kafka for event movement, event history, and integration between services.
For example, an ecommerce backend may use an API service to accept an order, a database to store the current order state, Kafka topics to publish order events, and consumers to update inventory, payments, analytics, and notifications.
Apache Kafka architecture reference links
For more details, refer to the Apache Kafka Streams Architecture, the Apache Kafka Protocol Guide, and the Apache Kafka Documentation.
FAQs on Apache Kafka architecture
What are the main components of Apache Kafka architecture?
The main components are producers, topics, partitions, brokers, consumers, consumer groups, offsets, stream processors, connectors, and cluster metadata controllers. These components work together to store and move event records across applications.
Is Kafka HTTP or TCP?
Kafka uses its native Kafka protocol over TCP for normal client-broker communication. HTTP can be used through an additional REST proxy or gateway, but it is not the core Kafka broker protocol.
Why use Kafka instead of only REST APIs?
Kafka and REST solve different problems. REST is suitable for direct request-response communication. Kafka is suitable for asynchronous event streaming, replayable logs, decoupled services, and cases where many consumers need to process the same events independently.
Is Apache Kafka a frontend or backend technology?
Apache Kafka is a backend infrastructure technology. It is normally used by backend services, data platforms, stream processors, and integration pipelines rather than by frontend user interfaces directly.
Can Kafka be used as the only backend database?
Kafka can store events durably for a configured retention period, but it is not usually used as the only backend database for an application. Most systems use Kafka with databases, caches, APIs, and processing services.
Editorial QA checklist for Apache Kafka architecture
- The article explains producers, consumers, topics, partitions, brokers, stream processors, and connectors in the context of Kafka architecture.
- The record life cycle makes clear that Kafka records are retained according to retention settings, not deleted when one consumer reads them.
- The article distinguishes older ZooKeeper-based Kafka architecture from current KRaft-based metadata management.
- The consumer group section explains offsets, partition assignment, and rebalancing in simple terms.
- The protocol section answers the common Kafka HTTP vs TCP question without presenting Kafka as a replacement for all REST APIs.
Conclusion :
We have learnt the Apache Kafka Architecture and its components in detail. Kafka architecture is centered on producers, topics, partitions, brokers, consumers, and stream processing applications. Producers write records to partitioned topics, brokers store and replicate those partitions, and consumers read records using offsets and consumer groups. Connectors and stream processors extend Kafka into databases, external systems, and event-driven workflows.