Cluster Managers in Apache Spark
The agenda of this tutorial is to understand what a cluster manager is, what it does in an Apache Spark application, and which cluster managers are supported in Spark. A Spark cluster manager is responsible for allocating resources on worker nodes so that Spark drivers and executors can run distributed jobs.
In simple terms, Apache Spark does the data processing, while the cluster manager decides where the processing resources come from. The driver program asks for resources, and the cluster manager starts or allocates executors on available worker machines.
What is a cluster in Apache Spark?
A cluster is a set of tightly or loosely coupled computers connected through LAN (Local Area Network). The computers in the cluster are usually called nodes. Each node in the cluster can have a separate hardware and Operating System or can share the same among them. Resource (Node) management and task execution in the nodes is controlled by a software called Cluster Manager.
In Spark terminology, a cluster normally contains one or more machines that can run executors. These executors perform the actual work such as reading data, transforming records, shuffling partitions, caching data, and writing results. The cluster manager is not the same as the Spark driver or executor; it is the resource allocation layer used by Spark.
What does a cluster manager do in an Apache Spark cluster?
The spark application contains a main program (main method in Java spark application), which is called driver program. Driver program contains an object of SparkContext. SparkContext could be configured with information like executors’ memory, number of executors, etc. Cluster Manager keeps track of the available resources (nodes) available in the cluster. When SparkContext object is created, it connects to the cluster manager to negotiate for executors. From the available nodes, cluster manager allocates some or all of the executors to the SparkContext based on the demand. Also, please note that multiple spark applications could be run on a single cluster. However the procedure is same, SparkContext of each spark application requests cluster manager for executors. In a nutshell, cluster manager allocates executors on nodes, for a spark application to run.
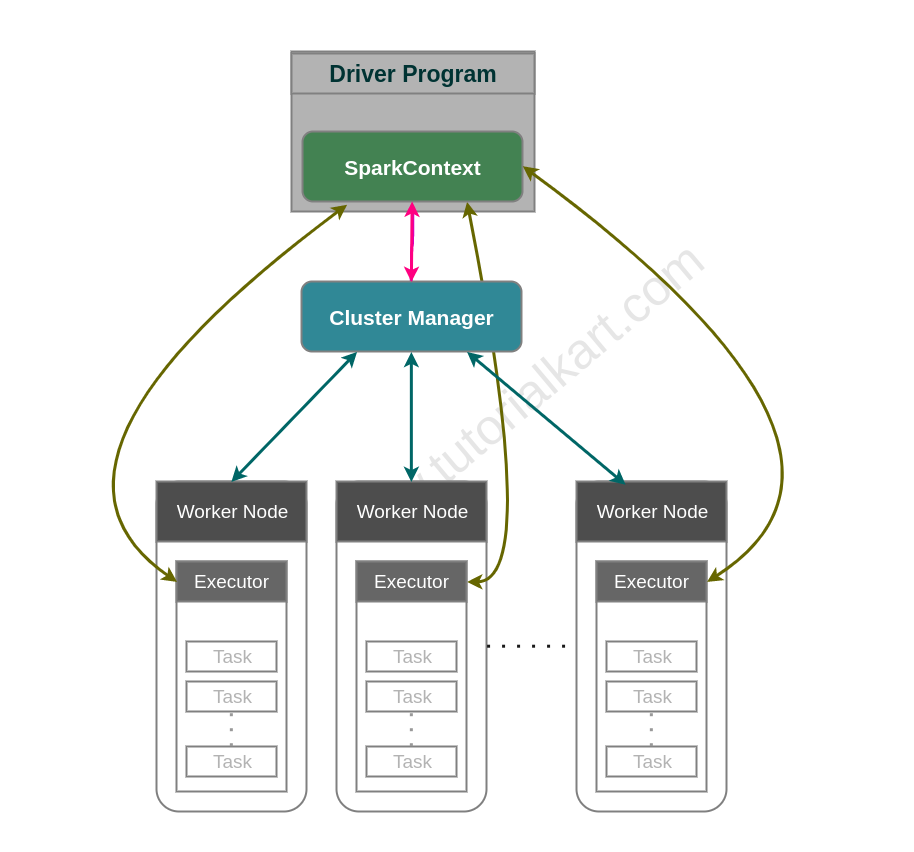
The cluster manager is involved mainly in resource negotiation and executor allocation. After executors are started, the Spark driver schedules tasks on those executors. This distinction is useful because the cluster manager does not decide every Spark task; Spark’s own scheduler handles task scheduling inside the application.
Spark driver, cluster manager, worker nodes, and executors
| Spark component | Role in the Spark cluster |
|---|---|
| Driver program | Runs the main application logic, creates SparkContext or SparkSession, and coordinates the Spark job. |
| Cluster manager | Allocates resources across nodes and starts or assigns executors for the Spark application. |
| Worker node | Machine in the cluster where executors can run. |
| Executor | Process that runs Spark tasks, stores cached data, and reports results back to the driver. |
| Task | Smallest unit of work scheduled by Spark on an executor. |
Cluster managers supported in Apache Spark
Following are the cluster managers available in Apache Spark.
Current Apache Spark documentation lists Spark Standalone, Hadoop YARN, and Kubernetes as supported cluster managers. Older Spark learning material may also mention Apache Mesos. Mesos was historically used with Spark, but for current Spark planning, prefer the cluster managers listed in the latest Spark documentation.
| Cluster manager | Best fit | How Spark usually connects |
|---|---|---|
| Spark Standalone | Simple Spark-only clusters and learning environments. | Driver connects to a Spark standalone master. |
| Hadoop YARN | Hadoop environments where YARN already manages resources. | Spark submits applications to YARN in client or cluster deploy mode. |
| Kubernetes | Containerized Spark workloads managed through Kubernetes. | Spark creates driver and executor pods through the Kubernetes API. |
| Apache Mesos | Legacy Spark deployments that already use Mesos. | Older Spark deployments used Mesos as a general cluster manager. |
Spark Standalone Cluster Manager
Standalone cluster manager is a simple cluster manager that comes included with the Spark.
Spark Standalone is often used for learning Spark architecture or for a Spark-only cluster where a separate resource manager is not required. It has a master process and worker processes. The master tracks available workers, and Spark applications request executor resources through the standalone master.
spark-submit \
--master spark://master-host:7077 \
--deploy-mode client \
application.pyUse Spark Standalone when you want a direct Spark cluster setup without Hadoop YARN or Kubernetes. It is also useful when the main goal is to understand Spark driver, worker, and executor behavior.
Hadoop YARN cluster manager for Spark
Hadoop YARN is the resource manager in Hadoop 2.
YARN is commonly used when Spark runs in a Hadoop-based data platform. In this setup, Spark applications are submitted to YARN, and YARN allocates containers for the driver and executors. This is useful when the same cluster also runs other Hadoop ecosystem workloads.
spark-submit \
--master yarn \
--deploy-mode cluster \
application.pyYARN supports both client mode and cluster mode. In client mode, the driver runs on the machine where the application is submitted. In cluster mode, the driver runs inside the cluster.
Kubernetes cluster manager for Spark applications
Kubernetes is a supported cluster manager for running Spark applications in containers. In a Kubernetes deployment, Spark can create a driver pod and executor pods. Kubernetes then handles pod scheduling, resource isolation, and container lifecycle management.
spark-submit \
--master k8s://https://kubernetes-api-server:6443 \
--deploy-mode cluster \
--name spark-kubernetes-example \
--class org.apache.spark.examples.SparkPi \
local:///opt/spark/examples/jars/spark-examples.jarUse Kubernetes when your environment already runs containerized workloads and Spark applications need to follow the same deployment model. Kubernetes setup requires container images, cluster access, namespace permissions, and Spark configuration suitable for the Kubernetes cluster.
Apache Mesos and older Spark cluster manager references
Apache Mesos is a general cluster manager that can also run Hadoop MapReduce and service applications.
Many older Spark tutorials mention Mesos along with Standalone and YARN. If you are maintaining an older Spark deployment, you may still see Mesos-related configuration. For new Spark installations, check the current Apache Spark cluster overview before choosing a cluster manager, because modern Spark deployments generally focus on Standalone, YARN, and Kubernetes.
Client mode and cluster mode with Spark cluster managers
The cluster manager is separate from the deploy mode. Deploy mode decides where the driver runs. In client mode, the driver runs on the machine that starts the application. In cluster mode, the driver runs inside the cluster. This difference matters for network access, logs, failure handling, and how long the submit machine must remain connected.
| Deploy mode | Where the Spark driver runs | Common use |
|---|---|---|
| Client mode | On the machine that submits the application. | Interactive work, debugging, and local development. |
| Cluster mode | Inside the cluster, managed by the cluster manager. | Scheduled jobs, production batch jobs, and long-running workloads. |
Choosing a cluster manager for Apache Spark
The right Spark cluster manager depends on the infrastructure already used by your organization or project. For a Spark-only setup, Spark Standalone is usually the easiest to understand. For Hadoop-based systems, YARN is a natural choice. For container-first platforms, Kubernetes is usually the better fit.
| Requirement | Suitable Spark cluster manager | Reason |
|---|---|---|
| Learning Spark cluster architecture | Spark Standalone | It is included with Spark and keeps the architecture simple. |
| Running Spark in an existing Hadoop environment | Hadoop YARN | YARN already manages resources across Hadoop workloads. |
| Running Spark with container orchestration | Kubernetes | Driver and executor processes can run as pods. |
| Maintaining an older Mesos-based platform | Apache Mesos | Relevant mainly for legacy deployments that already use Mesos. |
Spark master URLs for cluster managers
When submitting a Spark application, the --master value tells Spark which cluster manager or execution mode to use. The exact value depends on the cluster manager.
# Local mode for development
spark-submit --master local[*] application.py
# Spark Standalone cluster
spark-submit --master spark://master-host:7077 application.py
# Hadoop YARN cluster
spark-submit --master yarn application.py
# Kubernetes cluster
spark-submit --master k8s://https://kubernetes-api-server:6443 application.pyThese commands show the general pattern only. A real cluster may require additional options such as executor memory, number of executors, container image, queue name, namespace, authentication, or application class.
Official Apache Spark cluster manager references
For current details, refer to the Apache Spark documentation for Cluster Mode Overview, Submitting Applications, Running Spark on YARN, and Running Spark on Kubernetes.
FAQ about Apache Spark cluster managers
What are the different cluster managers in Spark?
Current Apache Spark documentation lists Spark Standalone, Hadoop YARN, and Kubernetes as supported cluster managers. Older Spark material may also mention Apache Mesos for legacy deployments.
What does a cluster manager do in Apache Spark?
A cluster manager allocates resources on worker nodes for Spark applications. The Spark driver connects to the cluster manager, requests resources, and receives executors where Spark tasks can run.
Is Spark Standalone the same as local mode?
No. Local mode runs Spark on a single machine for development or testing. Spark Standalone is a cluster manager that can run Spark applications across worker nodes.
Which Spark cluster manager should I choose for Hadoop?
For a Hadoop-based environment, Hadoop YARN is usually the suitable cluster manager because it already manages resources across Hadoop workloads.
Does the Spark cluster manager schedule every Spark task?
No. The cluster manager allocates resources and starts or assigns executors. Spark’s internal scheduler breaks jobs into stages and tasks, then schedules those tasks on executors.
Editorial QA checklist for this Spark cluster manager tutorial
- Confirm that the tutorial distinguishes the Spark driver, cluster manager, worker node, executor, and task.
- Check that the currently supported Spark cluster managers include Standalone, YARN, and Kubernetes.
- Ensure that Apache Mesos is described as an older or legacy Spark cluster manager reference, not the main recommendation for new setups.
- Verify that client mode and cluster mode are explained separately from the choice of cluster manager.
- Confirm that all new command examples use the
language-bash syntaxclass and that existing image and internal tutorial links are preserved.
Conclusion
In this Apache Spark Tutorial, we have learnt about the cluster managers available in Spark and how a spark application could be launched using these cluster managers. A Spark application uses the cluster manager to obtain executors, while the Spark driver coordinates jobs, stages, and tasks. For current Spark deployments, review Spark Standalone, Hadoop YARN, and Kubernetes, and choose the one that matches your infrastructure.