Configuring Apache Spark Ecosystem
Apache Spark configuration controls how a Spark application uses cluster resources, memory, CPU cores, executors, environment variables, and logging. A Spark job can run on a laptop, a standalone Spark cluster, YARN, Mesos, or Kubernetes, but the same basic configuration idea applies: decide which settings belong to the application, which belong to the cluster environment, and which belong to logging.
There are some parameters like number of nodes in the cluster, number of cores in each node, memory availability at each node, number of threads that could be launched, deployment mode, extra java options, extra library path, mapper properties, reducer properties, etc., that are dependent on the cluster setup or user preferences. These parameters are given control over, to the Apache Spark application user, to fit or configure Apache Spark ecosystem to the Spark application needs.
We shall learn the parameters available for configuration and what do they mean to the Spark ecosystem.
Following are the three broad categories of parameters where you can setup the configuration for Apache Spark ecosystem.
- Spark Application Parameters
- Spark Environment Parameters
- Logging Parameters
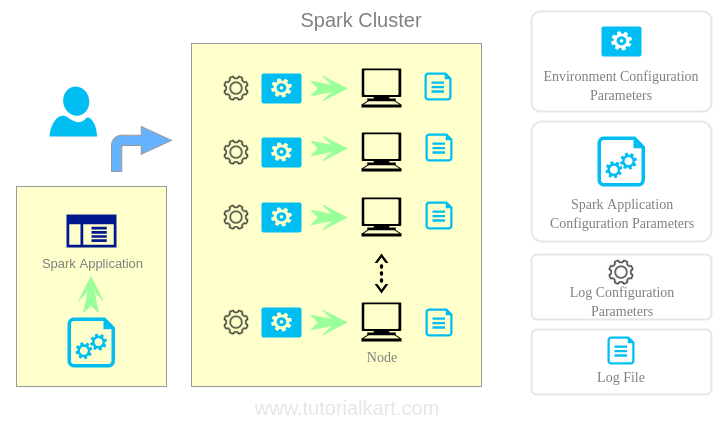
From the above figure :
- Spark Application Configuration Parameters are submitted to Driver Program by the user.
- Environment and Log Parameters are configured at worker nodes using shell script and logging properties file.
Apache Spark configuration files and command-line settings
In a typical Spark installation, configuration values are set from three places. Application-level properties are commonly set through SparkConf, Java system properties, or the spark-submit --conf option. Cluster environment values are set in spark-env.sh. Logging is configured through Spark’s logging properties file in the conf directory.
| Configuration area | Common file or method | What it controls |
|---|---|---|
| Spark application properties | SparkConf, spark-submit --conf, spark-defaults.conf | Application name, master URL, executor memory, executor cores, driver memory, shuffle behavior, serialization, SQL settings, and other Spark properties. |
| Spark environment variables | conf/spark-env.sh | Daemon memory, Java home, worker cores, worker memory, classpath, local directories, and variables needed when Spark services start. |
| Spark logging configuration | Logging properties file in conf | Log level, appenders, log format, and package-specific logging behavior for Spark applications and Spark daemons. |
When the same Spark property is set in more than one place, the value supplied directly to the application or through spark-submit is usually easier to see and manage for that job. Cluster-wide defaults are better suited to values that should apply to many applications on the same Spark installation.
Spark Application Parameters
These parameters effect only the behavior and working of Apache Spark application submitted by the user.
Following are the ways to setup Spark Application Parameters :
- Spark Application Parameters could be setup in the spark application itself using
SparkConfobject in the Driver program. - They could also be set using Java system properties if you are programming in a language runnable on JVM.
- These parameters could also provided by the user when submitting the spark application in the command prompt using
spark-submitcommand.
Setup Application Parameters using SparkConf
SparkConf is used to set Spark application parameters as key-value pairs.
Following are some of the setters that set respective parameters :
| SparkConf Method | Description |
| setAppName(String name) | Set a name for your application. |
| setExecutorEnv(scala.collection.Seq<scala.Tuple2<String,String>> variables) | Set multiple environment variables to be used when launching executors. |
| setExecutorEnv(String variable, String value) | Set an environment variable to be used when launching executors for this application. |
| setExecutorEnv(scala.Tuple2<String,String>[] variables) | Set multiple environment variables to be used when launching executors. |
| setIfMissing(String key, String value) | Set a parameter if it isn’t already configured |
| setJars(scala.collection.Seq<String> jars) | Set JAR files to distribute to the cluster. |
| setMaster(String master) | The master URL to connect to, such as “local” to run locally with one thread, “local[4]” to run locally with 4 cores, or “spark://master:7077” to run on a Spark standalone cluster. |
| setSparkHome(String home) | Set the location where Spark is installed on worker nodes. |
All the above methods return SparkConf with the parameter set. Hence chaining of these setters could be done as shown in the following example.
SparkConf sparkConf = new SparkConf().setAppName("Spark Application Name")
.setMaster("local[2]")
.set("spark.executor.memory","2g");The above example names the Spark application, runs it locally with two worker threads, and sets executor memory to 2g. This is useful for local testing, but production settings should be selected after checking dataset size, number of executors, CPU cores, cluster manager, and available memory on worker nodes.
Setup Spark application parameters using spark-submit
For packaged Spark applications, configuration is often supplied at submission time. This keeps resource settings outside the application code, so the same JAR or Python file can run with different memory and executor settings in development, testing, and production.
spark-submit \
--class com.example.SparkApplication \
--master spark://master-host:7077 \
--deploy-mode cluster \
--conf spark.executor.memory=4g \
--conf spark.executor.cores=2 \
--conf spark.executor.instances=4 \
target/spark-application.jarIn this command, --master tells Spark where to submit the job, --deploy-mode controls where the driver runs, and each --conf option supplies one Spark property. The exact resource values should match the cluster manager and the hardware available to the application.
Setup shared Spark defaults in spark-defaults.conf
If several Spark applications use the same base settings, place common properties in conf/spark-defaults.conf. This avoids repeating long command-line options for every submission. Application-specific values can still be supplied using spark-submit --conf when required.
spark.master spark://master-host:7077
spark.executor.memory 4g
spark.executor.cores 2
spark.driver.memory 2g
spark.serializer org.apache.spark.serializer.KryoSerializerUse spark-defaults.conf for stable defaults. Avoid hard-coding values that change frequently from job to job, such as executor count for a one-time batch job or a temporary debugging property.
Important Apache Spark application properties to review before submission
The Spark configuration list is large, but a beginner usually needs to understand a smaller group first. These properties affect where the job runs and how much CPU and memory it can use.
| Spark property | Purpose | Example value |
|---|---|---|
spark.master | Cluster manager or local mode URL used by the application. | local[2], spark://host:7077, yarn, k8s://... |
spark.app.name | Name shown in Spark UI and logs. | CustomerETLJob |
spark.driver.memory | Memory allocated to the Spark driver process. | 2g |
spark.executor.memory | Memory allocated to each executor process. | 4g |
spark.executor.cores | Number of CPU cores used by each executor. | 2 |
spark.executor.instances | Number of executor processes requested, when supported by the cluster manager. | 4 |
spark.local.dir | Local directories used for shuffle and temporary files. | /mnt/spark-tmp |
spark.serializer | Serializer used for Spark objects. | org.apache.spark.serializer.KryoSerializer |
Do not increase memory and core values blindly. More executor memory may reduce memory errors, but very large executors can increase garbage collection time. More cores per executor may improve parallelism, but too many cores in one executor can make tasks compete for memory and I/O. Start with moderate values and verify behavior with Spark UI, executor logs, and application metrics.
Spark Environment Parameters
These parameters effect the behavior and working and memory usage of nodes in the cluster.
To configure each node in the spark cluster individually, environment parameters has to be setup in spark-env.sh shell script. The location of spark-env.sh is <apache-installation-directory>/conf/spark-env.sh. To configure a particular node in the cluster, spark-env.sh file in the node has to setup with the required parameters.
If spark-env.sh is not present, start from the template file commonly provided in the Spark conf directory. Copy the template, rename it to spark-env.sh, and then add only the variables needed for that node or cluster.
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.shA simple standalone Spark worker configuration may look like this.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk
export SPARK_WORKER_CORES=4
export SPARK_WORKER_MEMORY=8g
export SPARK_LOCAL_DIRS=/mnt/spark-localEnvironment variables are evaluated when Spark daemons start. After changing spark-env.sh, restart the affected Spark services so the new values are applied.
Configuring Apache Spark cluster manager and deploy mode
The master URL and deploy mode decide where a Spark application runs and where the driver process lives. For local learning, local and local[n] are enough. For a cluster, the master value depends on whether Spark runs on standalone mode, YARN, Kubernetes, or another supported cluster manager.
| Run target | Typical master value | When to use it |
|---|---|---|
| Local mode | local, local[2], local[*] | Learning, unit testing, and small local experiments. |
| Spark standalone cluster | spark://host:7077 | Clusters managed directly by Spark standalone master and workers. |
| YARN | yarn | Hadoop environments where YARN manages cluster resources. |
| Kubernetes | k8s://... | Containerized Spark applications running on a Kubernetes cluster. |
In client deploy mode, the driver runs where spark-submit is executed. In cluster deploy mode, the driver runs inside the cluster. Client mode is convenient for debugging and interactive workflows. Cluster mode is more suitable for scheduled jobs because the application does not depend on the submit machine after submission.
Logging Parameters
These parameters effect the logging behavior of the running Apache Spark Application.
To configure logging parameters, modify the log4j.properties file with the required values and place it in the location <apache-installation-directory>/conf/log4j.properties. This can be done at node level i.e., logging properties for each node could be setup by placing the log4j.properties in the node at the specified location.
In newer Spark distributions, the logging template may use Log4j 2 naming, such as log4j2.properties.template. Use the logging template available in your Spark conf directory, copy it to the active logging file name expected by that Spark version, and then change log levels carefully.
rootLogger.level = warn
logger.spark.name = org.apache.spark
logger.spark.level = infoFor development, more detailed logs may help identify configuration mistakes. For production, avoid overly verbose logs unless debugging a specific issue, because excessive logging can make Spark applications slower and harder to inspect.
How to verify Apache Spark configuration after setup
After configuring Apache Spark, run a small job and verify the effective settings. The Spark UI is the easiest place to check application name, executors, driver details, storage, stages, tasks, and environment properties.
- Check that the application appears with the expected
spark.app.name. - Confirm the driver memory and executor memory shown in the environment tab.
- Verify the number of executors and cores used by the application.
- Review executor logs for Java path, classpath, permission, and memory errors.
- Confirm that local directories used for shuffle and temporary data have enough disk space.
A simple Spark shell command can also confirm whether the Spark installation starts correctly.
spark-shell --master local[2]If the shell starts successfully, run a small operation such as counting a range. This confirms that the driver, local execution, and basic Spark runtime are working.
spark.range(1, 1001).count()Common Apache Spark configuration mistakes
- Setting all values inside application code: Put environment-specific values in
spark-submitor defaults files so the same application can run in different environments. - Using more cores than the cluster can provide: Requested executor cores and instances must fit the available cluster resources.
- Ignoring driver memory: Some failures happen at the driver, especially when large results are collected to the driver process.
- Leaving local directories on small disks: Shuffle-heavy jobs need enough local disk space on worker nodes.
- Changing spark-env.sh without restarting services: Environment changes are applied when Spark daemons start, not automatically while they are already running.
- Making logs too verbose in production: Debug-level logging can create large log files and hide the actual error among many messages.
FAQ on how to configure Apache Spark ecosystem
What is the main file used to configure Spark application defaults?
spark-defaults.conf is commonly used to store default Spark application properties such as spark.master, spark.executor.memory, spark.driver.memory, and serializer settings. These defaults can still be overridden for a specific job using spark-submit --conf.
What is the difference between SparkConf and spark-submit –conf?
SparkConf sets properties inside the application code. spark-submit --conf sets properties when the application is submitted. Use SparkConf for values that are part of the application logic, and use spark-submit --conf for deployment-specific values such as memory, executor count, and cluster master.
Where should Spark worker memory and worker cores be configured?
For a Spark standalone cluster, worker-level values such as worker cores and worker memory are commonly set in conf/spark-env.sh on the worker node. After editing the file, restart the worker service so the new values are used.
How do I know whether my Spark configuration is actually applied?
Run a small Spark application and open the Spark UI. The environment and executor pages show many effective values, including driver settings, executor settings, Java properties, and classpath details. Executor logs also help confirm whether environment variables and logging changes were applied.
Should I configure Spark differently for local mode and cluster mode?
Yes. Local mode can use simple values such as local[2] and small memory settings. Cluster mode should be configured based on the cluster manager, worker resources, dataset size, shuffle volume, executor memory, executor cores, and driver placement.
Editorial QA checklist for Apache Spark ecosystem configuration
- Verify that the tutorial separates Spark application properties, Spark environment variables, and logging configuration.
- Check that all command-line examples use the
language-bashPrismJS class. - Confirm that syntax-only configuration snippets use a PrismJS language class with the
syntaxclass. - Ensure the existing Apache Spark configuration image and its URL remain unchanged.
- Review the examples for safe beginner defaults and avoid presenting one fixed executor or memory value as suitable for every cluster.
- Confirm that the tutorial explains both
SparkConfandspark-submit --confbecause users commonly search for both when configuring Spark.
Conclusion
In this Apache Spark Tutorial, we have learned how to configure an Apache Spark Ecosystem.
The practical approach is to keep application-specific settings in SparkConf or spark-submit, keep node and daemon settings in spark-env.sh, and manage logging through the Spark logging configuration file. After every change, run a small Spark job and verify the actual values in Spark UI and logs before using the configuration for larger workloads.