DAG (Directed Acyclic Graph) and Physical Execution Plan are core concepts in Apache Spark. Spark does not run every transformation immediately. It records transformations as a logical dependency graph, waits until an action is called, and then converts that graph into jobs, stages, and tasks that run on executors.
Understanding the Spark DAG and physical execution plan helps you read the Spark Web UI, find shuffle boundaries, and reason about performance. A DAG shows the dependency flow of operations. A physical execution plan shows how Spark schedules that flow across the cluster.
What is a DAG in graph theory?
DAG stands for Directed Acyclic Graph.
In graph theory, a graph is a collection of nodes connected by edges. A directed graph is a graph in which each edge has a direction from one node to another. A DAG is a directed graph with no cycle or loop. If you start at one node and follow the directed edges, you cannot return to a node that you have already visited.
What DAG means in Apache Spark execution
In Apache Spark, the DAG is the logical chain of dependencies created from transformations such as map, flatMap, filter, reduceByKey, join, and similar operations. The graph is directed because each operation depends on the output of an earlier operation. It is acyclic because Spark’s dependency chain moves from input data toward an action or output.
Unlike classic Hadoop MapReduce, where a developer often has to split a workflow into multiple MapReduce jobs manually, Spark can derive a dependency graph from the application code. The Spark driver identifies transformations, records their dependencies lazily, and builds a DAG. When an action is called, Spark uses that DAG to decide the jobs, stages, and tasks needed for execution.
This is why Spark transformations are described as lazy. A transformation adds a node or dependency to the plan, but it does not immediately scan the data. An action such as count(), collect(), saveAsTextFile(), or show() triggers execution.
DAG, job, stage, and task in Spark physical execution
A Spark application can contain one or more actions. Each action usually triggers a Spark job. The job is divided into stages at shuffle boundaries. Each stage is divided into tasks, and each task usually processes one partition of data.
| Spark term | Meaning | Example |
|---|---|---|
| DAG | Logical dependency graph built from transformations | textFile → flatMap → map → reduceByKey |
| Job | Execution triggered by an action | saveAsTextFile() |
| Stage | Group of tasks that can run without crossing a shuffle boundary | Map-side processing before reduceByKey |
| Task | Smallest scheduled unit of work sent to an executor | Processing one input partition |
| Shuffle | Redistribution of data across partitions | reduceByKey, groupByKey, many joins |
Execution Plan of Apache Spark
Execution Plan tells how Spark executes a Spark Program or Application. We shall understand the execution plan from the point of performance, and with the help of an example.
Consider the following word count example, where we shall count the number of occurrences of unique words.
counts = sc.textFile("/path/to/input/")
.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("/path/to/output/")Following are the operations that we are doing in the above program :
- Task 1 : Load input to an RDD
- Task 2 : Preprocess
- Task 3 : Map
- Task 4 : Reduce
- Task 5 : Save
It has to noted that for better performance, we have to keep the data in a pipeline and reduce the number of shuffles (between nodes). The data can be in a pipeline and not shuffled until an element in RDD is independent of other elements.
In our word count example, an element is a word. And from the tasks we listed above, until Task 3, i.e., Map, each word does not have any dependency on the other words. But in Task 4, Reduce, where all the words have to be reduced based on a function (aggregating word occurrences for unique words), shuffling of data is required between the nodes. When there is a need for shuffling, Spark sets that as a boundary between stages.
In the example, stage boundary is set between Task 3 and Task 4.
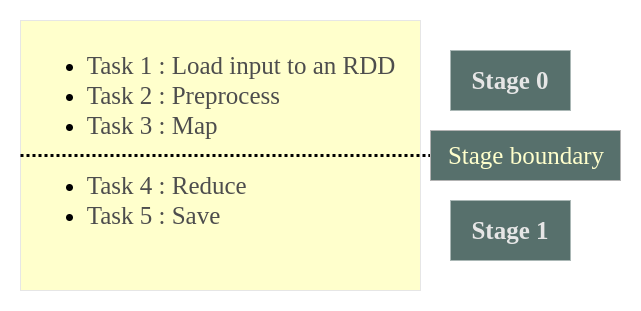
This stage boundary exists because reduceByKey groups values by key. Spark must make sure that all values for the same word reach the correct reduce-side partition. That redistribution is the shuffle. Operations before the shuffle can be pipelined together; operations after the shuffle form the next stage.
Narrow and wide transformations in Spark DAG stage boundaries
Spark decides many stage boundaries from dependency type. A narrow transformation can usually be executed by reading data from a single parent partition. A wide transformation needs data from multiple parent partitions and normally requires a shuffle.
| Transformation type | How it affects the Spark DAG | Examples |
|---|---|---|
| Narrow transformation | Can be pipelined inside the same stage | map, flatMap, filter, mapPartitions |
| Wide transformation | Usually creates a shuffle dependency and a new stage boundary | reduceByKey, groupByKey, distinct, many join operations, repartition |
A useful rule is: if Spark must move records across partitions so that related records meet, expect a shuffle and a stage boundary. Shuffles are not the only source of slow jobs, but they are usually one of the first places to inspect.
How to view the Spark DAG visualization in Spark Web UI
This could be visualized in Spark Web UI, once you run the WordCount example.
- Hit the url 192.168.0.104:4040/jobs/
- Click on the link under Job Description.
- Expand ‘DAG Visualization’
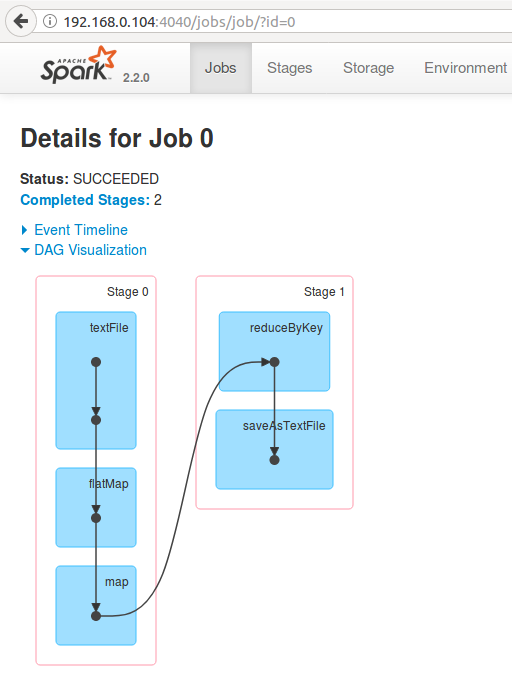
Tasks in each stage are bundled together and are sent to the executors (worker nodes).
On a local machine, the Spark Web UI is commonly available on port 4040 while the application is running. In a cluster environment, the exact URL depends on the cluster manager and deployment setup. The Jobs tab shows jobs created by actions. A job details page shows stages, tasks, and the DAG visualization for that job.
How Apache Spark builds a DAG and Physical Execution Plan ?
Following is a step-by-step process explaining how Apache Spark builds a DAG and Physical Execution Plan :
- User submits a spark application to the Apache Spark.
- Driver is the module that takes in the application from Spark side.
- Driver identifies transformations and actions present in the spark application. These identifications are the tasks.
- Based on the flow of program, these tasks are arranged in a graph like structure with directed flow of execution from task to task forming no loops in the graph (also called DAG). DAG is pure logical.
- This logical DAG is converted to Physical Execution Plan. Physical Execution Plan contains stages.
- Some of the subsequent tasks in DAG could be combined together in a single stage.
Based on the nature of transformations, Driver sets stage boundaries.
There are two transformations, namely narrow transformations and wide transformations, that can be applied on RDD(Resilient Distributed Databases).
narrow transformations : Transformations like Map and Filter that does not require the data to be shuffled across the partitions.
wide transformations : Transformations like ReduceByKey that does require the data to be shuffled across the partitions.
Transformation that requires data shuffling between partitions, i.e., a wide transformation results in stage boundary. - DAG Scheduler creates a Physical Execution Plan from the logical DAG. Physical Execution Plan contains tasks and are bundled to be sent to nodes of cluster.
In practical terms, Spark first records what has to be computed, then the DAG Scheduler splits the work into stages, and then task scheduling sends tasks to executors. A stage can contain multiple pipelined transformations when no shuffle is required between them.
DAG versus physical execution plan in Apache Spark
The DAG and the physical execution plan are related, but they are not the same thing. The DAG describes dependencies between operations. The physical execution plan describes how Spark will run those dependencies using jobs, stages, and tasks.
| Comparison point | Spark DAG | Physical execution plan |
|---|---|---|
| Purpose | Represents logical operation dependencies | Represents executable scheduling units |
| Created from | Transformations in the application | DAG after Spark identifies shuffle boundaries and stages |
| Main units | Operations and dependencies | Jobs, stages, and tasks |
| Where to inspect | DAG Visualization in Spark Web UI | Jobs, Stages, Tasks, SQL tabs, and explain output depending on API |
For RDD-based applications, the DAG is often discussed in terms of RDD lineage, dependencies, stages, and tasks. For DataFrame and Spark SQL applications, Spark also uses Catalyst optimization and query planning. In that case, you may see parsed logical plans, analyzed logical plans, optimized logical plans, and physical plans. These SQL/DataFrame plans are related to the same execution process, but they are displayed with different terminology from the RDD lineage view.
Reading Spark SQL physical plans with explain
When using DataFrames or Spark SQL, you can inspect the query plan with explain(). This helps you see whether Spark is scanning the expected source, pushing filters, using exchanges for shuffles, or applying joins in the expected way.
df.groupBy("word").count().explain(True)In Spark SQL physical plans, terms such as Exchange commonly indicate data redistribution, which is similar to the shuffle boundary idea discussed above. The exact output depends on Spark version, data source, configuration, and the query being executed.
Performance checks from Spark DAG and stage details
- Reduce unnecessary shuffles: Prefer transformations that avoid moving data when the same result can be achieved without redistribution.
- Use key-based aggregations carefully: Operations such as
reduceByKeyare useful, but they still create shuffle work. - Watch for skewed keys: If one key has far more records than others, one reduce-side task can become much slower than the rest.
- Check partition counts: Too few partitions can underuse the cluster, while too many tiny partitions can add scheduling overhead.
- Read stage metrics: Shuffle read/write, spill, task time, and input size often explain why a stage is slow.
Common misunderstandings about Spark DAG and physical execution plan
Beginners often confuse the logical DAG with the final physical work sent to executors. The DAG is the dependency structure, while the physical plan includes stages and tasks that Spark can schedule. Another common misunderstanding is that every transformation immediately starts a job. In Spark, transformations are lazy; actions trigger execution.
It is also useful to separate RDD terminology from Spark SQL terminology. RDD examples often discuss lineage, narrow dependencies, wide dependencies, stages, and tasks. DataFrame examples often discuss logical plans, optimized plans, physical plans, and query operators. Both views help explain execution, but they appear in different parts of Spark tooling.
Apache Spark DAG and physical execution plan FAQs
What is the difference between DAG and physical plan in Spark?
A DAG is the logical dependency graph of Spark operations. The physical plan is the executable plan Spark derives from that graph, including jobs, stages, and tasks. In Spark SQL, the physical plan also refers to the selected physical operators used to run a query.
Why does reduceByKey create a new stage in a Spark DAG?
reduceByKey groups values by key. Spark often has to move records across partitions so that values with the same key can be combined. This shuffle creates a stage boundary in the physical execution plan.
Does every Spark transformation create a separate stage?
No. Narrow transformations such as map, flatMap, and filter can usually be pipelined in the same stage. Wide transformations that require a shuffle usually start a new stage.
Where can I see the DAG for a running Spark job?
You can see it in the Spark Web UI. Open the Jobs tab for the running application, select a job, and expand the DAG Visualization section. The exact URL depends on where the Spark application is running.
Is Spark DAG only for RDD programs?
No. The concept of dependency-based execution exists across Spark. RDD applications show lineage and stage DAGs, while DataFrame and SQL applications also show logical and physical query plans through Spark SQL planning tools such as explain().
Editorial QA checklist for this Apache Spark DAG tutorial
- Confirms that a Spark DAG is a directed acyclic dependency graph, not the same as an executor task list.
- Explains lazy evaluation and clearly states that actions trigger Spark jobs.
- Connects wide transformations, shuffle, and stage boundaries using the word count example.
- Distinguishes RDD lineage terms from Spark SQL logical and physical plan terms.
- Keeps the Spark Web UI instructions tied to DAG Visualization, Jobs, Stages, and Tasks.
Summary of Spark DAG and physical execution plan
Apache Spark builds a DAG from transformations, waits for an action, and then converts the dependency graph into a physical execution plan. Narrow transformations can be pipelined inside a stage. Wide transformations usually require shuffling data and therefore create stage boundaries. By reading the Spark DAG visualization and stage metrics, you can understand how Spark moves from application code to distributed execution.