Spark MLlib TF-IDF
TF-IDF is one of the feature extractor Spark MLlib provides. In this tutorial, we shall learn about TF-IDF and how to implement TF-IDF using Spark MLlib.
What is TF-IDF ?
TF-IDF : Term Frequency – Inverse Document Frequency
In text mining, the input would be usually a corpus containing many documents. Documents contain terms (words or word-parts).
TF (Term Frequency) – In the context of term and document, TF is defined as the number of times a term appears in a document. Term and Document are independent variables and TF is dependent on these. Let us denote TF as a function of term (t) and document (d) : TF(t,d).
DF (Document Frequency) – In the context of term and all the documents in corpus, DF is defined as the number of documents that contain the term. Term and Document Corpus are independent variables and DF is dependent on these. Let us denote DF as a function of term (t) and document corpus (D) : DF(t,D).
When the requirement is to calculate importance of a term to a document in the corpus, TF denotes how important the term is to a document, but it does not address the context of corpus. DF addresses how important a term in the context of a documents corpus. If a term appears across all documents, the term is overemphasized by TF, but inverse of DF (IDF) could be used to project the actual importance of term, by calculating the product of TF and IDF.
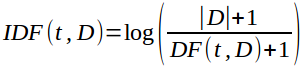
Note: Base of the log could be any number > 1.
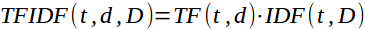
Consider the following text corpus containing three documents.
document1 : Welcome to TutorialKart. There are many tutorials covering various fields of technology.
document2 : Technology has advanced a lot with the invention of semi-conductor transistor. Technology is affecting our dailylife a lot.
document3 : You may find this tutorial on transistor technology interesting.TFIDF(technology, document2, corpus)
TF(technology, document2) = 2
IDF(technology, document2) = log((3+1)/(3+1)) = 0
TFIDF(technology, document2, corpus) = TF(technology, document2) . IDF(technology, document2) = 1 * 0 = 0
Even when the term ‘technology’ appeared twice in document2, as term has occurred in all the documents, it got no importance to document2 in the corpus.
TFIDF(TutorialKart, document1, corpus)
TF(TutorialKart, document1) = 1
IDF(TutorialKart, document1) = log((3+1)/(1+1)) = 1 (let’s take base as 2)
TFIDF(TutorialKart, document1, corpus) = TF(TutorialKart, document1) . IDF(TutorialKart, document1) = 1 * 1 = 1
The term ‘TutorialKart’ provides a TFIDF of 1.0 to document1 in the corpus.
How we perform TFIDF in Spark?
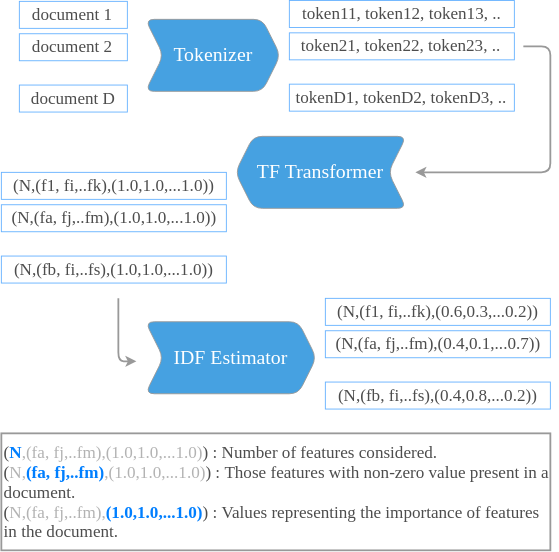
In Spark MLlib, TF and IDF are implemented separately.
- Term frequency vectors could be generated using HashingTF or CountVectorizer.
- IDF is an Estimator which is fit on a dataset and produces an IDFModel. The IDFModel takes feature vectors (generally created from HashingTF or CountVectorizer) and scales each column. Intuitively, it down-weights columns which appear frequently in a corpus.
Spark MLlib TF-IDF – Java Example
In the following example, we will write a Java program to perform TF-IDF of documents. We are taking documents as list of strings.
TFIDFExample.java
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.feature.HashingTF;
import org.apache.spark.ml.feature.IDF;
import org.apache.spark.ml.feature.IDFModel;
import org.apache.spark.ml.feature.Tokenizer;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class TFIDFExample {
public static void main(String[] args){
// create a spark session
SparkSession spark = SparkSession
.builder()
.appName("TFIDF Example")
.master("local[2]")
.enableHiveSupport()
.getOrCreate();
// documents corpus. each row is a document.
List<Row> data = Arrays.asList(
RowFactory.create(0.0, "Welcome to TutorialKart."),
RowFactory.create(0.0, "Learn Spark at TutorialKart."),
RowFactory.create(1.0, "Spark Mllib has TF-IDF.")
);
StructType schema = new StructType(new StructField[]{
new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("sentence", DataTypes.StringType, false, Metadata.empty())
});
// import data with the schema
Dataset<Row> sentenceData = spark.createDataFrame(data, schema);
// break sentence to words
Tokenizer tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words");
Dataset<Row> wordsData = tokenizer.transform(sentenceData);
// define Transformer, HashingTF
int numFeatures = 32;
HashingTF hashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("rawFeatures")
.setNumFeatures(numFeatures);
// transform words to feature vector
Dataset<Row> featurizedData = hashingTF.transform(wordsData);
System.out.println("TF vectorized data\n----------------------------------------");
for(Row row:featurizedData.collectAsList()){
System.out.println(row.get(3));
}
System.out.println(featurizedData.toJSON());
// IDF is an Estimator which is fit on a dataset and produces an IDFModel
IDF idf = new IDF().setInputCol("rawFeatures").setOutputCol("features");
IDFModel idfModel = idf.fit(featurizedData);
// The IDFModel takes feature vectors (generally created from HashingTF or CountVectorizer) and scales each column
Dataset<Row> rescaledData = idfModel.transform(featurizedData);
System.out.println("TF-IDF vectorized data\n----------------------------------------");
for(Row row:rescaledData.collectAsList()){
System.out.println(row.get(4));
}
System.out.println("Transformations\n----------------------------------------");
for(Row row:rescaledData.collectAsList()){
System.out.println(row);
}
spark.close();
}
}Output
TF vectorized data
----------------------------------------
(32,[20,28,29],[1.0,1.0,1.0])
(32,[1,4,15,28],[1.0,1.0,1.0,1.0])
(32,[1,2,4,9],[1.0,1.0,1.0,1.0])
TF-IDF vectorized data
----------------------------------------
(32,[20,28,29],[0.6931471805599453,0.28768207245178085,0.6931471805599453])
(32,[1,4,15,28],[0.28768207245178085,0.28768207245178085,0.6931471805599453,0.28768207245178085])
(32,[1,2,4,9],[0.28768207245178085,0.6931471805599453,0.28768207245178085,0.6931471805599453])
Transformations
----------------------------------------
[0.0,Welcome to TutorialKart.,WrappedArray(welcome, to, tutorialkart.),(32,[20,28,29],[1.0,1.0,1.0]),(32,[20,28,29],[0.6931471805599453,0.28768207245178085,0.6931471805599453])]
[0.0,Learn Spark at TutorialKart.,WrappedArray(learn, spark, at, tutorialkart.),(32,[1,4,15,28],[1.0,1.0,1.0,1.0]),(32,[1,4,15,28],[0.28768207245178085,0.28768207245178085,0.6931471805599453,0.28768207245178085])]
[1.0,Spark Mllib has TF-IDF.,WrappedArray(spark, mllib, has, tf-idf.),(32,[1,2,4,9],[1.0,1.0,1.0,1.0]),(32,[1,2,4,9],[0.28768207245178085,0.6931471805599453,0.28768207245178085,0.6931471805599453])]Now, let us implement the same use case in Python.
spark-mllib-tfidf.py
from __future__ import print_function
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("TfIdf Example")\
.getOrCreate()
sentenceData = spark.createDataFrame([
(0.0, "Welcome to TutorialKart."),
(0.0, "Learn Spark at TutorialKart."),
(1.0, "Spark Mllib has TF-IDF.")
], ["label", "sentence"])
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData)
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(wordsData)
# alternatively, CountVectorizer can also be used to get term frequency vectors
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show()
spark.stop()Execute the following command to submit this Python Application to Spark and run it.
$ spark-submit spark-mllib-tfidf.pyConclusion
In this Spark Tutorial, we have learnt about Spark Mllib TF-IDF, how to calculate TF and IDF, and how to realize TF-IDF using Spark MLlib HashingTF Transformer and IDF Estimator.